Talend „Job Design Modelle“ und Best Practices: Teil 1
Talend-Entwickler in aller Welt (und das betrifft Anfänger ebenso wie die Erfahrensten) sehen sich immer wieder mit einer ganz bestimmten Frage konfrontiert: „Wie codiere ich diesen Job am besten?“. Natürlich wissen wir, dass er effizient, einfach nachzuvollziehen, zu programmieren und vor allem (jedenfalls in den meisten Fällen) einfach zu warten sein sollte. Wir wissen auch, dass Talend Studio eine leere „Leinwand“ ist, auf die wir unseren Code „malen“, wobei wir eine reiche und farbenfrohe Palette von Komponenten, Repository-Objekten, Metadaten und Verknüpfungsoptionen nutzen. Aber wie können wir dabei sicher sein, dass unser Job-Design wirklich auf Best Practices basiert?
Job Design Modelle
Schon damals, als ich mit Version 3.4 erstmals Talend nutzte, waren mir Job-Designs sehr wichtig. Zunächst spielten bei der Entwicklung meiner Jobs Muster für mich keine Rolle. Ich hatte zuvor schon mit Microsoft SSIS und ähnlichen Tools gearbeitet und somit war ein visueller Editor wie Talend nichts Neues für mich. Stattdessen konzentrierte ich mich auf grundlegende Funktionalität und die Wiederverwendbarkeit von Code, dann auf das Canvas-Layout und ganz zum Schluss auf Namenskonventionen. Je mehr Talend Jobs ich für die verschiedensten Use-Cases entwickelte (es werden mittlerweile einige Hundert sein), desto ausgefeilter, recycelbarer und konsistenter wurde mein Code – und es wurden tatsächlich gewisse Muster erkennbar.
Seit Januar bin ich nun für Talend tätig und konnte bereits etliche von unseren Kunden entwickelte Jobs checken. Das bestätigte meine Einschätzung, dass es für jeden Entwickler und Use-Case wirklich eine Vielzahl von Lösungen gibt. Ich denke, das macht die Sache für viele von uns nicht einfacher. Wir Entwickler ticken ja alle irgendwie gleich und sind oft felsenfest davon überzeugt, dass der eigene Lösungsansatz der einzig richtige für einen bestimmten Entwicklungsjob ist. Aber irgendwann hocken wir dann doch voller Zweifel vor dem Monitor und fragen uns, ob es nicht vielleicht doch einen besseren Weg geben könnte. Das ist der Punkt, an dem wir anfangen, nach Best Practices zu suchen. In diesem Fall eben nach Job Design Modellen!
Die Basis definieren
Wenn ich überlege, wie ich bei einem bestimmten Job den bestmöglichen Code realisieren kann, greife ich automatisch auf ein paar „eherne Grundregeln“ zurück. Diese basieren auf jahrelanger Erfahrung, zahllosen Fehlschlägen und der kontinuierlichen Optimierung erfolgreicher Ansätze. Sie bilden eine solide Basis für die Entwicklung von Code und verdienen es (das ist jedenfalls meine bescheidene Meinung), sehr ernst genommen zu werden. Hier nun die Liste dieser Grundregeln, wobei die Reihenfolge völlig beliebig ist:
— Lesbarkeit: Code erstellen, der sich problemlos nachvollziehen lässt
— Einfachheit: einfachen, geradlinigen Code mit geringstmöglichem Zeitaufwand erstellen
— Wartungsfreundlichkeit: bei aller Komplexität minimale Auswirkungen von Änderungen sicherstellen
— Funktionalität: Code erstellen, der den Anforderungen gerecht wird
— Wiederverwendbarkeit: Erstellung teilbarer Objekte und modularer Arbeitseinheiten
— Konformität: Durchsetzung echter Disziplin über alle Teams, Projekte, Speicherorte und Codes hinweg
— Geschmeidigkeit: Code erstellen, der biegsam, aber unzerbrechlich ist
— Skalierbarkeit: Erstellung elastischer Module, die sich bei Bedarf dem Durchsatz anpassen
— Konsistenz: Realisierung durchgehend einheitlicher Strukturen bei allem
— Effizienz: Gewährleistung optimierter Datenflüsse und Nutzung von Komponenten
— Separierung: Erstellung modularer, klar ausgerichteter Bausteine, die nur einem Zweck dienen
— Optimierung: Gewährleistung maximaler Funktionalität bei der minimal möglichen Codemenge
— Performance: Erstellung effizienter Module, die den größtmöglichen Durchsatz bieten
Der Schlüssel zum Erfolg liegt in der ausgewogenen Anwendung dieser Grundregeln. Das gilt vor allem für die ersten drei, da diese in ständigem Widerspruch zueinander stehen. Zwei lassen sich meistens realisieren, aber oft muss man dann die dritte opfern. Vielleicht versuchen Sie einfach mal, diese Liste nach Prioritäten zu ordnen! Es wird Ihnen nicht leicht fallen.
Leitlinien sind KEINE Standards – es geht um Disziplin!
Bevor wir wirklich ins Thema Job Design Modelle eintauchen können, sollten wir uns mit ein paar weiteren wichtigen Details vertraut machen – ohne dabei allerdings die eben vorgestellten Grundregeln zu vergessen. Oft stoße ich bei Projekten auf starre Standards, die beim Eintritt unerwarteter Situationen zu einem unüberwindlichen Hindernis werden. Aber ich finde leider auch allzu oft das Gegenteil: unflexiblen, nachlässig geschriebenen und unstimmigen Code von verschiedenen Entwicklern, die im Prinzip alle den gleichen Fehler machen – oder schlimmer noch, Entwickler, die ohne Not verwirrenden und zusammenhanglosen Code von sich geben und so für Chaos sorgen. Ehrlich gesagt, kann ich derartige Schlampereien nicht ausstehen – zumal sie sich ganz einfach vermeiden lassen.
Aus diesen und anderen recht offensichtlichen Gründen ziehe ich es vor, Leitlinien zu entwickeln und zu dokumentieren statt Standards.
Diese umfassen alle Grundregeln sowie dazugehörige Spezifika. Werden auf dieser Basis Entwicklungsleitlinien definiert, die für alle in den Softwareentwicklungs-Lebenszyklus involvierten Teams gelten, unterstützt das Struktur, Definition und Kontext. Macht man sich diese Vorgehensweise zu eigen, profitiert man langfristig von Resultaten, mit denen alle zufrieden sind.
Hier eine Basis für solche Leitlinien, die Sie vielleicht für sich nutzen können (ändern und/oder erweitern Sie diese ruhig nach Gusto – ist ja schließlich nur eine Leitlinie ...)
- Methodiken, mit denen Sie festlegen können WIE Sie vorgehen wollen
- Datenmodellierung
- Ganzheitlich / Konzeptionell / Logisch / Physikalisch
- Datenbank, NoSQL, EDW, Dateien
- SDLC-Prozesssteuerung
- Waterfall oder Agile/Scrum
- Anforderungen & Spezifikationen
- Fehlerbehandlung & Auditing
- Data-Governance & Stewardship
- Datenmodellierung
- Technologien, die TOOLS (intern & extern) benennen sollten und in welcher Beziehung diese zueinander stehen
- Betriebssystem & Topologie der Infrastruktur
- Datenbankmanagementsysteme
- NoSQL-Systeme
- Verschlüsselung & Kompression
- Integration von Drittanbietersoftware
- Webservice-Oberflächen
- Externe Systemschnittstellen
- Best Practices, die beschreiben sollten, WELCHE Leitlinien WANN zu befolgen sind
- Umgebungen (DEV/QA/UAT/PROD)
- Namenskonventionen
- Projekte, Jobs & Joblets
- Repository-Objekte
- Logging, Monitoring & Benachrichtigungen
- Job-Return-Codes
- Code-Routinen (Java)
- Kontextgruppen & globale Variablen
- Datenbank- & NoSQL-Verbindungen
- Schemata für Source- und Target-Daten und -Dateien
- Job-Entry- & Job-Exit-Punkte
- Job-Workflow & Layout
- Komponentennutzung
- Parallelisierung
- Datenqualität
- Parent-/Child-Jobs & -Joblets
- Datenaustauschprotokolle
- Kontinuierliche Integration & Bereitstellung
- Integrierte Quellcodekontrolle (SVN/GIT)
- Release-Management & Versionierung
- Automatisierte Tests
- Artefakt-Repository & Promotion
- Administration & Betrieb
- Konfiguration
- User-Sicherheit & Autorisierung
- Rollen & Berechtigungen
- Projektmanagement
- Aufgaben, Termine & Trigger
- Archive & Desaster-Recovery
Zudem empfehle ich, die folgenden zusätzlichen Dokumente zu entwickeln und zu pflegen:
— Modularchiv: beschreibt alle wiederverwendbaren Projekte, Methoden, Objekte, Joblets & Kontextgruppen
— Datenwörterbuch: beschreibt alle Datenschemata & relevante gespeicherte Abläufe
— Datenzugriffsebene: beschreibt alles, was für den Zugriff auf und die Modifizierung von Daten erforderlich ist
Natürlich dauert es seine Zeit, diese Art von Dokumentation zu erstellen, aber auf lange Sicht überwiegt der Nutzen die Kosten bei weitem. Halten Sie die Dinge einfach, direkt und aktuell (es soll ja kein Manifest werden) und Ihre Dokumentation wird dafür sorgen, dass Ihre Projekte deutlich erfolgreicher verlaufen, einfach weil die Zahl der Entwicklungsfehler drastisch sinkt – und die können bekanntlich noch viel teurer werden.
Können wir jetzt endlich über Job Design Modelle sprechen?
Klar doch. Aber erst noch eines: Ich bin davon überzeugt, dass sich jeder Entwickler beim Schreiben von Code sowohl gute als auch schlechte Gewohnheiten aneignen kann. Auf den guten aufzubauen, ist entscheidend. Beginnen Sie mit einigen ganz simplen Gewohnheiten, wie z. B. stets alle Komponenten mit einem Label zu versehen. Das macht den Code lesbarer und verständlicher (eine der Grundregeln). Haben sich alle diese Vorgehensweise zu eigen gemacht, stellen Sie sicher, dass alle Jobs sauber in den entsprechenden Repository-Ordnern abgelegt werden und so benannt werden, dass sie sich den jeweiligen Projekten zuordnen lassen (stimmt genau: Konformität). Dann sollten alle dieselbe Art von Logging-Messages verwenden, vielleicht mit einem einheitlichen Method-Wrapper um die System.out.PrintLn()-Funktion. Zudem sollten sie einheitliche Kriterien für die Entry- und Exit-Punkte definieren, mit Optionen für alternative Anforderungen und Job-Code (damit schlagen Sie gleich mehrere Grundregeln mit einer Klappe). Wenn sich die Entwicklerteams erst einmal daran gewöhnt haben, nach durchdachten Entwicklungsleitlinien zu arbeiten, ist Ihr Projektcode deutlich einfacher zu lesen, zu schreiben und (mein Lieblingspunkt) zu warten – und zwar von allen Teammitgliedern.
Job Design Modelle und Best Practices
Ich sehe Talend Job Design Modelle als Vorlagen oder Roh-Layouts, die für bestimmte Use-Cases bereits essenzielle und/oder erforderliche Elemente enthalten. Das Wort Pattern, also Muster, ist hier durchaus zutreffend, da sie häufig für ähnlich gelagerte Projekte wiederverwendet werden können, was die Codeentwicklung beschleunigt. Wie Sie vermutlich erwarten, existieren auch einige allgemein verwendbare Muster, die sich für verschiedene Use-Cases eignen. Werden diese korrekt identifiziert und implementiert, kann das die gesamte Codebasis stärken, den Aufwand reduzieren und sich wiederholenden, aber ähnlichen Code reduzieren. Also starten wir am besten genau dort.
Hier sind 7 Best Practices, die Sie beachten sollten:
Canvas-Workflow & Layout
Es gibt viele Möglichkeiten, Komponenten auf dem Job-Canvas zu platzieren und ebenso viele, um sie miteinander zu verknüpfen. Ich ziehe es vor, zunächst von oben nach unten und dann nach links und rechts zu arbeiten, wobei ein nach links gerichteter Flow in der Regel ein Error-Pfad ist, während ein nach rechts oder unten gerichteter Flow der erwünschte oder normale Pfad ist. Vermeiden Sie dabei, wenn möglich, sich selbst kreuzende Verbindungslinien. Ab Version 6.0.1 unterstützen die hübsch geschwungenen Linien diese Strategie ziemlich gut.
Ich persönlich mag keine Zickzack-Muster, bei denen Komponenten in Reihe von links nach rechts angeordnet werden. Ist dann die rechte Kante erreicht, geht es einen Schritt nach unten und die Karawane zieht wieder nach links, und so weiter und so fort. Ich finde diese Anordnung grauenhaft und schwer zu warten, aber natürlich ist sie einfach zu schreiben. Nutzen Sie dieses Format, wenn es denn unbedingt sein muss, aber bedenken Sie: Ein Zickzack-Muster könnte darauf hinwiesen, dass der Job mehr tut, als er sollte, oder dass er nicht richtig organisiert ist.
Modulare Job-Bausteine – Parent-/Child-Jobs
Ein großer Job mit zahlreichen Komponenten ist schwer nachzuvollziehen und zu warten. Das lässt sich vermeiden, wenn Sie ihn in kleinere Jobs oder Einheiten herunterbrechen, wo immer das möglich ist. Dann führen Sie diese als Child-Jobs des Parent-Jobs aus (über die tRunJob Komponente), deren Zweck unter anderem auch die Kontrolle und Ausführung dieser Jobs ist. So können Sie auch besser Fehler korrigieren und die nächsten Schritte bestimmen. Vergessen Sie nicht, ein schlampig angelegter Job ist schwer nachzuvollziehen, erschwert das Debuggen/Reparieren und ist nahezu nicht zu warten. Simple, kleinere Jobs, die einen klaren Zweck haben, gehen schnell von der Hand, lassen sich fast immer einfach debuggen/reparieren und erleichtern die Wartung.
Zwar ist es völlig akzeptabel, Parent-/Child-Hierarchien zu schaffen, es gibt in der Praxis aber einige Einschränkungen. Je nach Speichernutzung, Parametern, Bedenken hinsichtlich Tests/Debuggen und Parallelisierungstechniken (weiter unten beschrieben) sollte ein gutes Job Design Muster maximal drei tRunJob-Parent-/Child-Calls beinhalten. Gewiss ist es sicher, weitere Ebenen hinzuzufügen, aber ich denke, bei allen Use-Cases sollten fünf Level in jedem Fall ausreichen.
tRunJob vs. Joblets
Der simple Unterschied zwischen einem Child-Job und einem Joblet liegt darin, dass ersterer von Ihrem Job aufgerufen wird, während ein Joblet Teil des Jobs ist. Beide bieten die Möglichkeit, wiederverwendbare und/oder generische Codemodule zu entwickeln. Eine besonders effiziente Strategie bei jedem Job Design Muster wäre es, deren Nutzung korrekt zu integrieren.
Entry- und Exit-Punkte
Alle Talend Jobs müssen irgendwo starten und enden. Talend bietet dafür zwei grundlegende Komponenten: tPreJob und tPostJob. Ihr Zweck ist es, zu kontrollieren, was passiert, bevor und nachdem der Content eines Jobs ausgeführt wird. Ich sehe die beiden als Initialize- und WrapUp-Schritte in meinem Code. Sie verhalten sich, wie man es erwarten würde: Zuerst wird tPreJob ausgeführt, gefolgt von echtem Code. Abschließend wird dann der tPostJob-Code ausgeführt. Bitte beachten Sie, dass der tPostJob-Code unabhängig von möglicherweise im Code integrierten Exits ausgeführt wird (wie z. B. eine tDie-Komponente oder eine Komponenten-Checkbox-Option mit die on error-Funktion).
Die Verwendung der Komponenten tWarn und tDie sollten Sie auch in die Planung Ihrer Job-Entry- und Job-Exit-Punkte mit einbeziehen. Sie bieten eine programmierbare Kontrolle darüber, wo und wie ein Job abgeschlossen werden soll. Zudem verbessern sie die Fehlerbehandlung, das Logging und Recovery-Möglichkeiten.
Ich nutze bei diesem Job Design Muster gerne tPreJob, um Kontextvariablen zu initialisieren, Verbindungen herzustellen und wichtige Informationen zu erfassen, und am Ende tPostJob, um Verbindungen zu schließen, andere wichtige Aufräumaufgaben auszuführen und natürlich für noch mehr Logging. Ziemlich einfach, oder? Machen Sie es auch so?
Fehlerbehandlung und Logging
Dies ist sehr wichtig, vielleicht sogar essenziell. Denn wenn Sie ein einheitliches Job Design Muster korrekt erstellen, lässt sich ein extrem wiederverwendbarer Mechanismus in nahezu all Ihren Projekten nutzen. Mein Job Pattern ist es, ein logPROCESSING-Joblet zu erstellen, um einen konsistenten, wartungsfähigen Logging-Prozessor zu schaffen, der sich für alle Jobs nutzen lässt. ZUDEM integriere ich sauber definierte Return-Codes, die für Konformität, Wiederverwendbarkeit und hohe Effizienz sorgen. Merke: Was sich einfach schreiben lässt, ist einfach zu lesen und ... richtig ... einfach zu warten. Ich bin sicher, sobald Sie Ihren Weg für die Fehlerbehandlung und das Logging in Ihren Projektaufgaben entwickelt haben, wird dies ein breites Grinsen auf Ihr Gesicht zaubern.
Aktuelle Talend-Versionen bieten jetzt auch Support für die Nutzung von Log4j und einem Log-Server. Aktivieren Sie einfach die Menüoption Project Settings>Log4j und konfigurieren Sie den Logstash-Server im TAC. Es ist definitiv zu empfehlen, diese grundlegende Funktionalität in Ihre Jobs zu integrieren.
OnSubJobOK/ERROR vs OnComponentOK/ERROR (& Run If) Komponenten-Links
Wo genau der Unterschied zwischen dem On SubJob- und dem On Component-Link liegt, ist für viele Talend-User nicht wirklich klar. Bei OK und ERROR ist die Sache logisch. Wo also liegen bei diesen Trigger Connections die Unterschiede und wie beeinflussen diese den Flow eines Job-Designs?
Trigger Connections zwischen Komponenten definieren die Verarbeitungssequenz und den Datenfluss, wo immer in einem Subjob Abhängigkeiten zwischen einzelnen Komponenten bestehen. Subjobs werden durch eine Komponente charakterisiert, mit der eine oder mehrere andere Komponenten verknüpft sind, um den aktuellen Datenfluss zu ermöglichen. In einem Job kann es zahlreiche Subjobs geben, deren Komponenten in der Standardeinstellung über eine blau markierte Box gekennzeichnet sind (lässt sich in der Werkzeugleiste deaktivieren).
Ein On Subjob OK/ERROR-Trigger setzt den Prozess bis zum nächsten verlinkten Subjob fort, nachdem die Verarbeitung aller Komponenten innerhalb des Subjobs abgeschlossen wurde. Diese Funktion sollte nur von der Startkomponente des Subjobs genutzt werden. Ein On Component OK/ERROR-Trigger setzt dann den Prozess bis zur nächsten verlinkten Komponente fort, nachdem die Bearbeitung dieser spezifischen Komponente abgeschlossen wurde. Ein Run If-Trigger kann sehr hilfreich sein, wenn die Fortführung des Prozesses zur nächsten verlinkten Komponente auf einem programmierbaren Java-Ausdruck basiert.
Was ist ein Job-Loop?
Entscheidend für nahezu jedes Job Design Muster sind der Main Loop sowie alle Secondary Loops im Code. An diesen Punkten erfolgt die Kontrolle des potenziellen Exits einer Jobausführung. Der Main Loop wird in der Regel durch die oberste Verarbeitungsebene eines Datenflussergebnisses repräsentiert. Ist die Verarbeitung abgeschlossen, ist der Job beendet. Secondary Loops sind in eine höhere Loop-Ebene eingebettet und erfordern oft beträchtliche Kontrolle, um den korrekten Exit eines Jobs zu gewährleisten. Ich identifiziere immer den Main Loop und stelle sicher, dass ich der Kontrollkomponente eine tWarn- und eine tDie-Komponente hinzufüge. Die tDie-Komponente ist normalerweise so eingestellt, dass sie den JVM-Exit sofort auslöst (beachten Sie aber bitte, dass sogar dann der tPostJob-Code ausgeführt wird). Diese Top-Level-Exit-Punkte verwenden eine simple 0 für den Erfolgs-Return-Code und eine 1 für den Fehler-Return-Code, aber am besten folgen Sie Ihrer eigenen Return-Codes-Richtlinie. Secondary Loops (und andere kritische Komponenten im Fluss) eignen sich sehr gut, um weitere tWarn- und tDie-Komponenten zu integrieren (wenn die tDie-Komponente NICHT auf sofortigen JVM-Exit eingestellt ist).
Die meisten der oben besprochenen Job Design Muster Best Practices werden unten visuell dargestellt. Bitte beachten Sie, dass ich trotz meiner Vorliebe für sinnvolle Komponenten-Label die Regeln der Komponenten-Platzierung doch ein wenig frei interpretiert habe. Aber wie dem auch sei, das Ergebnis ist ein leicht lesbarer, wartungsfreundlicher Job, der sich vergleichsweise schnell schreiben ließ.
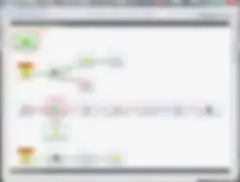
Fazit
Vermutlich ist es mir nicht gelungen, hier ALL Ihre Fragen zum Thema Job Design Muster zu beantworten. Aber ein guter Anfang war es hoffentlich schon ... Ich habe einige wichtige Grundlagen vorgestellt und Ihnen zeigen können, wie sich die einzelnen Abläufe optimal strukturieren lassen. Ich hoffe, Sie fanden die Lektüre interessant und konnten ihr die eine oder andere Anregung entnehmen.
Um wirklich alles abzudecken, muss ich wohl noch einen Blogpost zu diesem Thema schreiben (oder besser gleich mehrere). Nun denn, im nächsten wird es um einige wichtige Themen sowie verschiedene Use-Cases gehen, denen wir auf die eine oder andere Weise begegnen können. Außerdem arbeitet das Customer Success Architecture-Team an einem Talend Mustercode, um diese Use-Cases zu unterstützen. Kunden mit entsprechendem Abo können schon bald im Talend Help Center auf diese zugreifen. Schauen Sie einfach mal vorbei.
Ressourcen zu diesem Thema
5 Ways to Become A Data Integration Hero
Erwähnte Produkte

Weitere Artikel zu diesem Thema
- Was sind Datensilos?
- Datenextraktion – Eine Definition
- Talend „Job Design Patterns“ und Best Practices: Teil 4
- Talend „Job Design Patterns“ und Best Practices: Teil 3
- Was ist Datenmigration?
- Was ist Daten-Mapping?
- Datenbankintegration: Vorteile, Arten und Instrumente
- Was ist Datenintegration?
- Datenmigration verstehen: Strategie und Best Practices
- Talend Job Design Modelle und Best Practices: Teil 2
- Change Data Capture: Informationen und Anwendungsmöglichkeiten
- 5 erfolgreiche Datenintegrationsstrategien
- Ein Talend Überblick für Informatica PowerCenter-Entwickler: Teil 1