Talend Job Design Modelle und Best Practices: Teil 2
Es freut mich sehr, dass mein vorheriger Blogeintrag „Talend Job Design Patterns und Best Practices“ so gut angekommen ist. Vielen Dank an alle, die ihn gelesen haben! Falls Sie noch nicht dazu gekommen sind, sollten Sie ihn jetzt gleich lesen – der zweite Teil baut nämlich auf dem ersten Teil auf und geht mehr ins Detail. Außerdem werde ich auch ein paar fortgeschrittene Themen anschneiden. Sind Sie bereit für noch mehr interessante Infos? Dann mal los!
Job-Designs – erste Schritte
Als erfahrener Talend-Entwickler finde ich es immer interessant zu sehen, wie andere ihre Jobs erstellen. Nutzen sie Features auf die richtige Weise? Verwenden sie einen bekannten Stil oder einen, den ich noch nie gesehen habe? Haben sie eine ganz eigene coole Lösung entwickelt? Oder überfordert sie der abstrakte Charakter des Canvas/Workflows bzw. der Komponentendaten so sehr, dass sie sich auf einen Holzweg ins Nirgendwo begeben? Unabhängig von den Antworten auf diese Fragen finde ich es sehr wichtig, das Tool zu nutzen, da es genau zu diesem Zweck konzipiert wurde. In diesem Sinne habe ich mich dazu entschlossen, das Thema Job Design Modelleund die entsprechenden Best Practices zu beleuchten. Für mich ist das grundlegende Bedürfnis – nachdem man alle Features und Funktionen von Talend kennengelernt hat – immer noch dasselbe: Jobs auf die bestmögliche Art und Weise zu erstellen!
Logischerweise ist der Business-Use-Case der entscheidende Faktor für alle Talend-Jobs. In der Tat habe ich viele unterschiedliche Variationen desselben Workflows und viele verschiedene Varianten von Workflows gesehen. Die meisten dieser Use-Cases gehen von der Grundannahme aus, dass ein Datenintegrationsjob in seiner einfachsten Form Daten aus irgendeiner Quelle extrahiert und verarbeitet, möglicherweise im weiteren Verlauf transformiert und schließlich in irgendein Zielsystem lädt. ETL-/ELT-Code ist daher unser Lebenselixier, und wir Talend-Entwickler erstellen ihn. Ich möchte Sie also nicht mit etwas langweilen, was Sie bereits kennen. Lassen Sie uns stattdessen unseren Horizont erweitern ...
Ohne Zweifel ist das neueste Talend-Release (v6.1.1) die beste Version, mit der ich jemals gearbeitet habe. Mit all den neuen Komponenten für Big Data, Spark und maschinelles Lernen, der überarbeiteten Benutzeroberfläche und automatisierten Funktionen für kontinuierliche Integration/Implementierung (um nur ein paar wenige Highlights zu nennen) ist dies für mich die robusteste und funktionsreichste Datenintegrationstechnologie auf dem Markt. Okay, ich bin vielleicht etwas befangen, aber ich kann mich auch in Ihre Lage als Kunden versetzen, da ich einmal in derselben Situation war. Sie können also auf meine Einschätzung vertrauen, aber machen Sie sich ruhig selbst ein Bild davon.
3 Grundlagen für erfolgreiche DI-Projekte
Bestimmt würden Sie mir zustimmen, dass ein Stuhl ohne mindestens drei Beine nicht stehen kann, oder? Dasselbe gilt auch für die Entwicklung von Software. Für die Erstellung und Bereitstellung erfolgreicher Datenintegrationsprojekte kommt es insbesondere auf drei Elemente an:
- Use-Case – eine gut definierte Anforderung für Unternehmensdaten/Workflows
- Technologie – die Tools, mit denen wir die Lösung erstellen, implementieren und ausführen
- Methode – eine von allen akzeptierte Art und Weise, Dinge zu tun
Nachdem wir das besprochen und gut durchdachte Entwicklungsleitlinien definiert haben (haben Sie meinen vorherigen Blogeintrag gelesen und haben Sie ein solches Dokument für Ihr Projekt erstellt?), können wir auf diesen Anforderungen aufbauen.
Über die Grundlagen hinaus
Wenn Talend-Jobs die Technologie in einem Use-Case-Workflow darstellen, dann sind Job Design Modelle die beste Methode, um sie zu generieren. Wenn Sie nichts anderes aus meinen Blogeinträgen mitnehmen können, dann achten Sie zumindest bei der Erstellung Ihrer Jobs auf Einheitlichkeit! Wenn Sie eine bessere Methode gefunden haben und sie funktioniert, ist das super; ändern Sie nichts. Aber wenn Sie Probleme mit der Performance, Wiederverwendbarkeit und Wartbarkeit haben oder Sie ständig Code an die veränderten Anforderungen anpassen müssen, dann werden diese Best Practices für Sie als Talend-Entwickler ein große Hilfe sein!
9 weitere Best Practices:
Softwareentwicklungs-Lebenszyklus (SDLC)
Dem Milliardär Marcus Lemonis (The Profit, CNBC) zufolge entscheiden Personen, Produkte und Prozesse über den Erfolg oder Misserfolg von Unternehmen. Dem kann ich nur zustimmen! Der SDLC-Prozess ist für jedes Softwareentwicklungsteam ein entscheidender Faktor. Es ist extrem wichtig, hier alles richtig zu machen; ignoriert man diesen Prozess, wird das Projekt ernsthaft beeinträchtigt, was häufig zum Scheitern führt. Der SDLC-Best-Practices-Leitfaden von Talend bietet einen umfassenden Einblick in die Konzepte, Prinzipien, Spezifikationen und Details von Continuous-Integration- und -Deployment-Features, die für Talend-Entwickler verfügbar sind. Ich empfehle allen Softwareentwicklungsteams wärmstens, eine SDLC-Best-Practice in ihre Entwicklungsleitlinien (s. meinen vorherigen Blogeintrag dieser Reihe) zu integrieren und konsequent umzusetzen.
Der richtige Umgang mit dem Arbeitsbereich
Wenn Sie Talend Studio auf Ihrem Laptop bzw. Ihrer Workstation installieren (vorausgesetzt, Sie haben Adminrechte), wird in der Regel ein Standard-Workspace-Verzeichnis auf der lokalen Festplatte erstellt. Wie bei vielen Softwareinstallationen befindet sich der Speicherort standardmäßig innerhalb des Verzeichnisses, in dem ausführbare Dateien platziert werden. Meiner Meinung nach ist das nicht wirklich eine gute Praxis. Aber warum?
Lokale Kopien von Projektdateien (Jobs und Repository-Metadaten) werden in diesem Arbeitsbereich (Workspace)gespeichert und wenn sie mit einem Quellcode-Kontrollsystem (d. h. SVN oder GIT) über das Talend Administration Center (TAC) verknüpft werden, erfolgt eine Synchronisierung, sobald Sie ein Projekt öffnen und sobald Objekte gespeichert werden. Für mich sollten diese Dateien an einem Ort gespeichert werden, der eine einfache Identifizierung und Verwaltung zulässt, vorzugsweise an einem anderen Ort auf der Festplatte (oder sogar auf einer komplett anderen lokalen Festplatte).
Um es klar auszudrücken: Ein Arbeitsbereich wird verwendet, wenn Sie eine beliebige Verbindung in Talend Studio erstellen. Dabei kann es sich um eine lokale Verbindung oder eine Remote-Verbindung handeln; der Unterschied liegt darin, dass eine lokale Verbindung nicht durch das TAC verwaltet wird, eine Remote-Verbindung hingegen schon. Für unsere Abokunden wird in der Regel nur die Remote-Verbindung genutzt.
Die Organisation Ihrer Verzeichnisstruktur sollte klar in Ihren Entwicklungsleitlinien beschrieben sein und von Ihrem gesamten Team beherzigt werden, um eine optimale Zusammenarbeit zu garantieren. Hier kommt es darauf an, sich auf einen Prozess zu einigen, der für Ihr Team funktioniert, und diesen konsequent und diszipliniert umzusetzen.
Referenzprojekte
Nutzen Sie Referenzprojekte? Wissen Sie, was das ist? Mir ist aufgefallen, dass viele unserer Kunden dieses einfache, aber extrem produktive Feature gar nicht kennen. Wir alle möchten wiederverwendbaren, gemeinsamen oder allgemeinen Code erstellen, der sich über alle Projekte hinweg nutzen lässt. Ich habe oft gesehen, wie Entwickler ein Projekt öffnen, ein Codefragment kopieren und dann in ein separates (oder manchmal in dasselbe) Projekt bzw. einen separaten Job einfügen. Viele exportieren auch Objekte aus einem Projekt und importieren sie dann in ein anderes. Ich muss zugeben, dass ich das früher auch gemacht habe. Diese Methoden funktionieren im Prinzip zwar, sollten aber vermieden werden, da sie in einem regelrechten Wartungsalbtraum enden können – wie wahrscheinlich viele von Ihnen wissen, die das aus eigener Erfahrung kennen. ABER KEINE SORGE! Es gibt eine bessere Methode: Referenzprojekte! Sie können sich gar nicht vorstellen, wie froh ich war, als ich sie entdeckt habe!
Wenn Sie Projekte mithilfe der TAC erstellt haben, ist Ihnen vielleicht ein unauffälliges Auswahlkästchen mit dem Namen Reference aufgefallen. Haben Sie sich je gefragt, wofür das ist? Wenn Sie ein Projekt erstellen und dieses Kästchen aktivieren, wird dieses Projekt zu einem Referenzprojekt, das Sie dann in jedes beliebige andere Projekt einbinden (Include) bzw. damit verknüpfen (Link) können. Code, den Sie in diesem Referenzprojekterstellt haben, ist in diesen verknüpften Projekten (schreibgeschützt) verfügbar, was ihn hochgradig wiederverwendbar macht. Das ist genau der richtige Ort, um all Ihre gemeinsamen Objekte und Ihren gemeinsamen Code zu erstellen.

Sie sollten die Anzahl dieser Referenzprojekte allerdings auf ein Minimum begrenzen. Wir empfehlen, nur ein Referenzprojekt als Best Practice zu erstellen, wobei in einigen Fällen auch mehrere (2 oder 3) möglich sind. ACHTUNG: Zu viele Referenzprojekte sind kontraproduktiv, übertreiben Sie es also nicht. Wichtig ist, sie sehr sorgfältig zu pflegen; Sie sollten deren Nutzung und Regeln klar in Ihren Entwicklungsleitlinien definieren und das gesamte Team sollte diese für eine optimale Zusammenarbeit umsetzen.
Namenskonventionen für Objekte
Man sollte das Kind beim Namen nennen.
Namenskonventionen sind extrem wichtig! Jedes Entwicklungsteam, das sein Geld wert ist, weiß dies auch und setzt das konsequent in der Praxis um. Unabhängig davon, wann, wie und welche Talend-Objektnamen angewendet werden, kommt es auch hier wieder einmal auf Konsistenz an. Die Namenskonventionen für Objekte in Talend sollten Sie klar in Ihren Entwicklungsleitlinien definieren und das gesamte Team sollte sich daran halten, um eine optimale Zusammenarbeit zu gewährleisten (na, können Sie schon ein Muster erkennen?).
Projekt-Repository
Wenn Sie Ihr Projekt in Talend Studio (Eclipse-IDE (integrierte Entwicklungsumgebung) bzw. einfach ausgedrückt: Job-Editor) öffnen, entspricht das linke Feld dem Projekt-Repository. Hier befinden sich alle Ihre Projektobjekte sowie einige sehr wichtige Bereiche. Natürlich sollten Sie die „Job Designs“-Bereiche kennen, die in v6.1.1 mit drei unterschiedlichen Jobtypen erweitert wurden (Datenintegration, Batch, Streaming), aber es gibt auch andere Bereiche, die Sie kennen und nutzen sollten.
- Kontextgruppen – anstatt integrierte Job-Kontextvariablen zu generieren, erstellen Sie sie einfach in einer Kontextgruppe im Repository. So können Sie diese über alle Jobs (und Projekte, wenn sie in ein Referenzprojekt integriert sind) hinweg wiederverwenden. Definieren Sie klare Gruppen gemäß Ihren Anforderungen. Am besten sollten Sie Gruppen für Ihre unterschiedlichen Umgebungen erstellen: SBX/DEV/TEST/UAT/PROD. Wenn DEV nicht die Standardeinstellung ist, stellen Sie DEV als Standardeinstellung ein.

Ich habe eine Kontextvariable (SysENVTYPE) hinzugefügt, die den Wert für eine dynamische Programmierung innerhalb einer ausgewählten Umgebung enthält. Mit anderen Worten: Ich nutze diese Variable innerhalb eines Jobs, um die aktuelle Umgebung zur Laufzeit zu bestimmen. So kann ich meinen Flow durch bedingte Logik programmatisch anpassen.
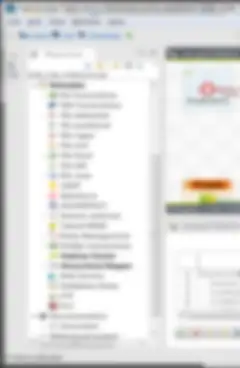
- Metadaten – Metadaten gibt es in vielen verschiedenen Formen; nutzen Sie sie alle! Datenbankverbindungen und deren Tabellenschemata, Flatfile-Layouts aller Art (.csv; .xml; .json etc.) und das nützliche allgemeine Schema, das sich auf so viele verschiedene Arten nutzen lässt, dass ich gar nicht alle auflisten kann (das würde hier den Rahmen bei weitem sprengen).
- Dokumentation – generieren Sie Ihr eigenes Projekt-Wiki und stellen Sie es Ihrem Team bereit. Mit diesem Feature können Sie eine Reihe benutzerfreundlicher HTML-Dateien zu Ihrem Projekt erstellen – das ist wirklich sehr nützlich und es dauert nur ein paar Minuten.
Für Ihr Team sollten Sie ein paar Best Practices in Ihrem Entwicklungsleitlinien-Dokument erstellen und sich daran halten. Passen Sie diese nach Bedarf an und achten Sie darauf, das gesamte Team einzubinden.
Versionskontrolle (Branching und Tagging)
Vielleicht ist Ihnen aufgefallen, dass es in jedem Job-Eigenschaften-Tab möglich ist, „M“ajor- und „m“inor-Schemata für die Versionsnummerierung zu nutzen. Darüber hinaus können Sie einen individuell konzipierten Status einrichten, der als Standardoptionen Entwicklung, Test und Produktion umfasst. ACHTUNG: Diese sind für Entwickler gedacht, die alleine arbeiten (TOS: Talend Open Studio) und nicht den Vorteil einer kooperativen Entwicklung und Quellcodekontrolle in SVN-/GIT-Repositorys haben. Was Sie wissen müssen: Jedes Mal, wenn Sie diese internen Jobeigenschaften mit einer höheren Versionsnummer versehen, wird eine vollständige Kopie des Jobs in Ihrem lokalen Canvas erstellt und mit dem Quellcode-Kontrollsystem synchronisiert. Ich habe einige Projekte gesehen, in denen nach über einem Dutzend interner Version-Bumps Jobkopien erstellt wurden. ALLE Kopien dieses Jobs werden vervielfältigt, was eine enorme Menge untergeordneter Dateien zur Folge hat, die alle mit dem Quellcode-Kontrollsystem synchronisiert werden. Dies kann das Projekt überfrachten und ernste Performanceprobleme beim Öffnen und Schließen eines Projekts verursachen. Wenn das bei Ihnen vorkommt, müssen Sie Ihren Canvas aufräumen, indem Sie einen Export ausführen und nur die neueste Jobversion importieren. Glauben Sie mir, der Aufwand lohnt sich!
Stattdessen sollte man für die Versionskontrolle in allen bezahlten Subskriptionsumgebungen am besten die nativen Branching- und Tagging-Mechanismen für die Quellcodekontrolle nutzen. Das ist die beste Möglichkeit, Projektversions-Releases zu handhaben, da bei der Quellcodekontrolle lediglich die Deltainformationen für jede Jobspeicherung beibehalten werden. Auf diese Weise lässt sich der Speicherplatz für Jobs drastisch reduzieren. Erstellen Sie ein Versionierungsschema mit Zahlen, Daten oder anderen nützlichen Informationen und fügen Sie es Ihrem Entwicklungsleitlinien-Dokument hinzu. Sorgen Sie dafür, dass sich Ihr gesamtes Team an diesen Prozess hält (Sie sehen, letztendlich geht es immer um das Gleiche!).
Speicherverwaltung
Sie möchten also einen Job ausführen? Haben Sie die Speicheranforderungen beachtet? Umfasst der Job Millionen von Zeilen und/oder hat er viele Spalten und/oder viele Lookups in der tMap? Haben Sie berücksichtigt, dass, wenn der Job im Jobserver läuft, andere Jobs gleichzeitig laufen könnten? Haben Sie darüber nachgedacht, wie viele Kerne bzw. wie viel RAM dieser Jobserver hat? Wie haben Sie die tMap-Joins konfiguriert – Load Once oder Row by row? Ruft Ihr Job Child-Jobs auf oder wird Ihr Job von einem Parent-Job aufgerufen und wie viele Ebenen verschachtelter Jobs gibt es? Laufen die Child-Jobs in einer separaten JVM? Wissen Sie beim Schreiben von ESB-Jobs, wie viele Routen erstellt werden? Nutzen Sie Parallelisierungstechniken (siehe unten)? Und, haben Sie daran gedacht? Ich wette, nicht ...
Standardeinstellungen sind dazu gedacht, Basiswerte für konfigurierbare Einstellungen bereitzustellen. Jobs haben einige davon, zum Beispiel die Speicherzuweisung. Standardeinstellungen sind aber nicht immer ideal, ganz im Gegenteil. Ihr Use Case Job Design, Ihr Operational Ecosystem und Ihr Real Time JVM Thread Count bestimmen, wie viel Speicher genutzt wird. Sie müssen das alles im Griff haben.

Sie können die JVM-Speichereinstellungen auf Projektebene oder für spezifische Jobs (wie oben) definieren:
Preferences > Talend > Run
Sie sollten sich intensiv mit diesem Thema auseinandersetzen und alles richtig machen – ansonsten drohen große Probleme! In der Tat wird die Speicherverwaltung oft vernachlässigt – dabei ist es extrem wichtig, dass sowohl Entwicklungsteams als auch operative Teams die relevanten Richtlinien optimal dokumentieren und befolgen. ~Möchten Sie jetzt endlich den ersten Blogeintrag lesen?
Dynamische SQL-Syntax
Bei vielen Datenbank-Input-Komponenten ist eine geeignete SQL-Syntax im Basic Settings-Tab erforderlich. Natürlich kann man die Syntax einfach direkt in die tMyDBInput-Komponente eingeben, das ist schon in Ordnung; wenn eine komplexe SQL-Abfrage zur Laufzeit auf Basis irgendeiner einschränkenden Logik unter der Kontrolle des Jobs oder des Parent-Jobs dynamisch erstellt werden muss, gibt es eine relativ einfache Lösung für dieses Problem. Erstellen Sie Context Variables für die Grundkonstrukte der SQL-Abfrage, platzieren Sie sie im Job-Flow vor der tMyDBInput-Komponente und nutzen Sie dann die Kontextvariable anstelle einer hartcodierten Abfrage.
Zum Beispiel habe ich eine Context Group in einem Referenced-Projekt-Repository entwickelt, die ich SystemVARS nenne und die eine Reihe nützlicher und wiederverwendbarer Variablen enthält. Für das dynamische SQL-Paradigma definiere ich folgende String-Variablen, die mit null initialisiert sind:

Ich richte diese Variablen in einer tJava-Komponente entsprechend meinen Anforderungen ein und verknüpfe sie dann im tMyDBInput-Abfrage-Feld, etwa so:
“SELECT “ + Context.sqlCOLUMNS + Context.sqlFROM + Context.sqlWHERE
Ich füge immer einen Leerschritt am Ende des Variablenwerts ein, um eine saubere Verkettung sicherzustellen. Wenn mehr Kontrolle erforderlich ist, nutze ich ebenfalls eine sqlSYNTAX-Variable, steuere bedingt, wie ich die Klauseln der SQL-Syntax verkette, und platziere Context.sqlSYNTAX stattdessen einfach in das tMyDBInput-Abfrage-Feld. Voilà! Vielleicht ist das kein dynamischer SQL-Code aus Datenbank-Host-Sicht, aber es ist auf jeden Fall ein dynamisch generierter SQL-Code für Ihren Job!
Und noch einmal: Dokumentieren Sie diese Richtlinie und sorgen Sie dafür, dass Sie alle auf dieselbe Weise umsetzen!
Parallisierungsoptionen
Talend bietet mehrere Mechanismen für die Code-Parallelisierung. Wenn man diese korrekt und effizient einsetzt und dabei die potenziellen Auswirkungen für die CPU-Kern- und RAM-Nutzung berücksichtigt, kann man extrem leistungsstarke Job Design Patterns erstellen. Werfen wir einen Blick auf die Optionen:
- Ausführungsplan – mehrere Jobs/Aufgaben lassen sich so konfigurieren, dass sie parallel im TAC laufen
- Mehrere Jobflows – innerhalb eines einzigen Jobs lassen sich mehrere Datenflüsse starten, die alle denselben Thread haben. Diese Methode kann in seltenen Fällen genutzt werden, wenn keine Abhängigkeiten zwischen den Flows existieren. Generell vermeide ich sie, da ich lieber separate Jobs erstelle.
- Parent-/Child-Jobs – wenn Sie einen Child-Job mit der tRunJob-Komponente aufrufen, können Sie ein Häkchen im Auswahlfeld „Use an independent process to run subjob“ setzen, um einen separaten JVM-Heap/-Thread einzurichten, in dem der Child-Job ausgeführt wird. Dies ist genau genommen zwar keine Parallelisierung, bezieht aber den Child-Job mit ein.
- Komponenten – die tParallelize-Komponente verbindet mehrere Datenflüsse zur Ausführung; die tPartitioner-, tDepartitioner-, tCollector- und tRecollector-Komponenten bieten eine direkte Kontrolle über die Anzahl paralleler Threads für einen Datenfluss.
- DB-Komponenten – die meisten DB-Input-/-Output-Komponenten bieten eine erweiterte Einstellung, um die Parallelisierung von Thread-Counts auf bestimmten SQL-Anweisungen zu ermöglichen. Dies kann sehr effizient sein – eine zu hohe Anzahl kann aber das Gegenteil bewirken. Am besten sind 2 bis 5.
Es ist möglich, all diese Parallelisierungsmethoden zu kombinieren (sozusagen zu verschachteln) – allerdings sollte man hier sehr vorsichtig vorgehen. Sie sollten Ihren Speichernutzungsstack kennen! Achten Sie darauf, wie das Job Design Pattern ausgeführt wird. Beachten Sie, dass diese Parallelisierungsoptionen nur in den Talend-Plattform-Produkten als erweiterte Features verfügbar sind. Sie sollten die Parallelisierungsrichtlinien unbedingt in Ihrem Dokument aufführen!
Das Geheimnis erfolgreicher Talend-Jobs
Ich hoffe, Sie nutzen künftig diese Best Practices für Job Design Modelle, um optimale Talend-Jobs zu erstellen. Im Grunde kommt es für erfolgreiche Jobs vor allem auf Richtlinien, Disziplin und Konsistenz an. Man muss sich einfach nur dazu entscheiden und es dann konsequent umsetzen. Wenn Sie Ihren Code auf Ihre Daten-/Workflow-Leinwand malen, denken Sie daran:
„Taten sind der Schlüssel zum Erfolg!“ – Pablo Picasso
Zu guter Letzt habe ich einige Dos and Don’ts zusammengetragen, die meiner Meinung nach entscheidend für den Erfolg Ihrer Talend-Jobs sind:
- - Nutzen Sie sowohl dietPreJob- als auch die tPostJob-Komponente
- - Überfrachten Sie Ihren Canvas nicht mit eng gruppierten Komponenten, sondern verteilen Sie diese etwas
- - Achten Sie auf eine strukturierte Gestaltung Ihres Codes; von oben nach unten und von links nach rechts
- - Erwarten Sie nicht, dass Sie beim ersten Mal gleich alles richtig machen
- - Identifizieren Sie Ihren zentralen Job-Loop und steuern Sie Ihren Exit
- - Ignorieren Sie nicht die Methoden zur Fehlerbehebung
- - Nutzen Sie Kontextgruppen ausgiebig (DEV/QA/UAT/PROD) und weise
- - Erstellen Sie nicht zu viele einzelne Job-Layouts
- - Erstellen Sie modulare Jobbausteine
- - Vermeiden Sie zu viel Komplexität; vereinfachen Sie Ihre Prozesse
- - Nutzen Sie allgemeine Schemata in allen Bereichen (eine vertretbare Ausnahme ist das Ein-Spalten-Schema)
- - Vergessen Sie nicht, Ihre Objekte zu benennen
- - Nutzen Sie, wo angebracht, Joblets (möglicherweise gibt es nur ein paar davon)
- - Verzichten Sie auf einen übermäßigen Gebrauch der tJavaFlex-Komponente; tJava oder tJavaRow reichen vermutlich aus
- - Sie sollten die Projektdokumentation generieren/veröffentlichen, sobald Sie fertig ist
- - Stellen Sie unbedingt den Runtime-Memory-Heap ein
Fazit
Ist das genug? Haben Sie sich sattgelesen? Hoffentlich nicht, denn ich plane noch weitere Blogeinträge zu dieser Reihe: „Beispiel-Use-Cases“! Im heutigen Blogeintrag
haben wir die Grundlagen erweitert und uns mit einigen fortgeschrittenen Konzepten beschäftigt. Ich hoffe, dass Sie wichtige Erkenntnisse für sich gewinnen konnten. Hinterlassen Sie gerne einen Kommentar zu den Best Practices – dies soll kein Monolog werden, sondern eine Grundlage für interessante Gespräche liefern. Bis zum nächsten Beitrag ...
Ressourcen zu diesem Thema
Erwähnte Produkte

Weitere Artikel zu diesem Thema
- Was sind Datensilos?
- Datenextraktion – Eine Definition
- Talend „Job Design Patterns“ und Best Practices: Teil 4
- Talend „Job Design Patterns“ und Best Practices: Teil 3
- Was ist Datenmigration?
- Was ist Daten-Mapping?
- Datenbankintegration: Vorteile, Arten und Instrumente
- Was ist Datenintegration?
- Datenmigration verstehen: Strategie und Best Practices
- Talend „Job Design Modelle“ und Best Practices: Teil 1
- Change Data Capture: Informationen und Anwendungsmöglichkeiten
- 5 erfolgreiche Datenintegrationsstrategien
- Ein Talend Überblick für Informatica PowerCenter-Entwickler: Teil 1