Talend “Modèles de Conception de Job” et Bonnes Pratiques : 1e partie
Tous les développeurs Talend, des débutants aux plus expérimentés, se posent souvent cette question : “Quelle est la meilleure manière de réaliser ce traitement ?” Nous voulons qu'il soit efficace, facile à lire, facile à concevoir, et par-dessus tout (dans la plupart des cas), facile à maintenir. Le studio Talend est un tableau blanc sur lequel nous dessinons notre programme à l'aide d'une riche palette de composants colorés et cohérents, objets du repository, Métadonnées et options des connexions. Nous sommes des artistes de la programmation. Comment pouvons-nous alors être certains que nous avons bien appliqué les meilleurs techniques ? Car, finalement, Talend offre une telle richesse de composants qu'il y a toujours plusieurs manières de réaliser la même tâche.
Modèles de Conception de Job
Depuis la version 3.4, quand j'ai commencé à utiliser Talend, une bonne analyse et conception des jobs était déjà primordiale pour moi. Au tout début je ne résonnais pas en termes de patterns lorsque je concevais mes jobs. Auparavant, j' utilisais Microsoft SSIS et Informatica, éditeur graphique aussi - Talend n'était pas nouveau pour moi. Je me focalisais plutôt sur les fonctionnalités simples, la réutilisabilité du code (via les groupes de contextes, les shémas génériques, les hiérarchies de jobs, et les codes de retour), ensuite l'organisation du plan de travail (comme le placement des composants, la direction des workflows, les liens entre objets, et les options de configuration), et finalement les conventions de nommage. Aujourd'hui, après avoir développé des centaines de traitements avec Talend pour une grande variété de use cases, je constate que mon code devient plus raffiné, plus réutilisable, plus cohérent, et des modèles de conception ont commencé à émerger.
Depuis que j'ai rejoint Talend en janvier de cette année (2015), j'ai eu l'occasion de maintenir le code développé par nos clients. Cela a confirmé mon point de vue qu'il y a en effet de multiples solutions pour chaque problème. Ceci est en fait la source du problème pour beaucoup d'entre nous. Nous les développeurs, pensons généralement de la même manière, mais bien souvent nous pensons que notre façon de développer est la meilleure ou la seule pour réaliser un job particulier. Intrinsèquement, nous entendons aussi cette petite voix, ce petit démon, qui tranquillement installé sur notre épaule nous hante en nous chuchotant à l'oreille, que peut-être, juste peut-être, il y aurait une autre façon, bien meilleure, de faire les choses. C'est alors que, saisi d'un irrésistible doute, nous cherchons et demandons quelles seraient ces bonnes pratiques: c'est à dire – Le Saint Graal des Modèles de Conception de Job !
Exprimons les concepts de base
Quand je cherche à évaluer ce qui est requis pour réaliser le meilleur code qui soit, les préceptes fondamentaux sont toujours de rigueur. Ils proviennent d'années d'expériences acquises sur nos erreurs et que nous avons améliorées avec succès. Ils représentent les concepts primordiaux qui créent les fondations sur lesquelles construire notre code et devraient être (à mon humble avis) prises très au sérieux. Je pense qu'elles incluent (sans ordre particulier d'importance) :
- La lisibilité : créer un code qui puisse être rapidement analysé et compris.
- Une écriture concise : vite et bien : créer rapidement, un code simple en un minimum de temps.
- La maintenabilité : réduire au stricte minimum la complexité afin d'avoir un impact tout aussi minime lors des évolutions.
- L'exactitude : créer un code qui réponde précisément au besoin.
- La réutilisabilité : créer des objets partageables et des tâches atomiques qui soient réutilisables.
- Le respect des règles : mettre en place une réelle discipline entre les équipes, les projets, les « repository », et le code. Autrement dit, imposer et respecter des règles de travail, de nommage, et d'écriture.
- La robustesse : créer un code qui plie mais ne casse pas. Autrement dit qui réagisse bien lorsque l’on s’écarte des conditions normales d’utilisation.
- L'extensibilité : créer des modules élastiques qui puissent s'adapter à la demande.
- La cohérence : créer des choses basiques avant tout.
- L'efficience : réaliser des flux de données et composants optimaux.
- Le cloisonnement : créer des modules atomiques, ciblés qui répondent à un seul et unique besoin. Evitez les couteaux suisses !
- L'optimisation : réaliser le plus de fonctionnalités possibles avec le moins de code possible.
- La performance : réaliser des modules efficaces qui fournissent les débits les plus rapides.
Parvenir à un véritable équilibre entre ces préceptes est la clef : en particulier en ce qui concerne les 3 premiers, car ils sont en parfaite contradiction les uns avec les autres. Vous en obtenez souvent 2 au sacrifice du troisième. Tâchez alors de les ordonner par ordre d'importance, si vous le pouvez !
Des lignes de conduite mais PAS de standard ~ Tout est question de discipline !
Avant que nous plongions véritablement dans les Modèles de Conception de Job, et en corrélation avec ces principes de base qui viennent d'être illustrés, assurons-nous que nous comprenons certains détails additionnels qui doivent être pris en considération. Je fais souvent face à des standards rigides qui ne laissent aucune place pour l’inattendu, l'incontrôlable et/ou l'inhabituel ce qui provoque généralement des failles dans ces derniers. Je rencontre aussi, bien trop souvent, le contraire : code inflexible, hirsute, incongru et de différents développeurs faisant essentiellement la même chose; pire encore, des développeurs propageant un désordre confus dans un chaos décousu et non planifié. Franchement, je trouve qu'il s'agit d'un travail bâclé et maladroit car il ne faudrait que peu d'effort pour l'éviter.
Pour ces raisons et d'autres assez évidentes, je préfère nommer ce document ‘ligne de conduite’, et non ‘Standards’. Celles-ci englobent les préceptes fondamentaux et y ajoutent quelques autres plus spécifiques. Lorsqu'un ‘Guide des bonnes pratiques de développement’ est créé et adopté par toutes les équipes impliquées dans le SDLC (Software Development Life Cycle), les fondations sont posées pour supporter la structure. En investissant sur ce dernier, et sur le long terme, vous obtiendrez des résultats où tout le monde trouvera satisfaction !
Voici une proposition de plan que vous pouvez utiliser comme bon vous semble (n'hésitez pas à le modifier, le compléter; Et n’oubliez pas : ce n'est qu'un guide!).
- Les Méthodes qui doivent détailler COMMENT vous souhaitez bâtir votre univers.
- Modélisation de données
- Holistique / Conceptuel / logique / physique
- Base de données, NoSQL, EDW, Fichiers
- Maîtrise du Processus SDLC
- Cycle en V ou Agile/Scrum
- Cahier des charges & Specifications
- Gestion des erreurs & Superivion
- Gouvernance & Architecte de données
- Modélisation de données
- Les Technologies qui doivent lister les OUTILS (internes et externes) et comment elles interagissent
- OS & Topologie de l'infrastructure
- Systèmes de Gestion de Base de Données
- Systèmes NoSQL
- Chiffrement & Compression
- Intégration de logiciels tiers
- Interfaces avec les Web Services
- Interfaces avec les systèmes externes
- Bonnes pratiques qui doivent décrire QUOI & QUAND certaines recommandations doivent être appliquées
- Environnements (DEV/QA/Recette/PROD)
- Conventions de nommage
- Projets, Jobs & Joblets
- Objets du Repository
- Logging, Monitoring & Notifications
- Codes de retour des jobs
- Code (Java) Routines
- Groupes de contextes & Variables globales
- Bases de données & Connections NoSQL
- Données Sources et Cibles & Schémas des fichiers
- Entrée des Jobs & Points de sortie
- Workflow des jobs & schémas
- Cas d'utilisation des composants
- Parallélisation
- Qualité des données
- Jobs Parents/Fils & Joblets
- Protocoles d'échange de données
- Integration continue & Deploiement
- Gestion intégrée de code source (SVN/GIT)
- Gestion des livraisons & versionnement
- Tests automatisés
- Artéfact Repository & Promotion
- Administration & Opérations
- Configuration
- Sécurité & Autorisations
- Roles & Permissions
- Gestion de projet
- Batch de jobs
- Sauvegardes & Reprise après sinistre
Quelques documents complémentaires pourraient aussi, je pense, être rédigés et mis à jour, incluant :
- Les bibliothèques de modules : décrivant tous les éléments réutilisables: projets, méthodes, objets, joblets, & groupes de contextes
- Les dictionnaires de données : décrivant tous les schémas de données & procédures stockées associées
- Couches d'accès aux données : décrivant tout ce qui est pertinent pour se connecter et manipuler les données
Il est indéniable que créer des documents comme ceux-ci requerra du temps, mais le gain, durant leur utilisation, dépassera de loin leur coût. Gardez-les simple, clairs, à jour, (nul besoin d'en faire un manifeste) et ils contribueront en grande partie au succès de vos projets en diminuant drastiquement les erreurs de développement (qui s'avèrent généralement bien plus coûteuses).
Et maintenant pouvons-nous aborder les bonnes pratiques ?
Assurément! Mais auparavant: une dernière chose. J'ai l'intime conviction que tout développeur est capable du pire comme du meilleur lorsqu'il programme. Construire avec des bonnes pratiques est vital. Commencez par des règles simples, comme nommer tous vos composants avec un label explicite. Ceci rend votre code plus lisible et compréhensible (l'un de nos préceptes fondamentaux). Une fois que chacun a repris cette règle, veillez à ce que tous vos jobs soient soigneusement organisés dans des dossiers ayant un nom significatif pour votre projet (oui, nous parlons de conformité). Ensuite assurez-vous que tout le monde adopte les mêmes règles de formatage pour les messages de logs, peut-être en utilisant une méthode « proxy » basée sur la fonction System.out.PrintLn()function; puis établissez un critère commun d'entrée / sortie suffisamment ouverts pour s'adapter à d'autres besoins, pour le code de vos jobs (ces 2 éléments permettent de remplir plusieurs de nos préceptes à la fois). Avec le temps, comme les équipes de développement utiliseront des règles de développement bien définies, le code de votre projet deviendra plus facile à lire, écrire, et (ce que je préfère) à maintenir par n'importe quel développeur de votre équipe.
Modèles de Conception de Job & Bonnes Pratiques
Pour moi, les 'jobs design patterns' sont des propositions de modèles ou squelettes de conception de jobs impliquant des éléments essentiels et/ou nécessaires à la réalisation de cas d'études particuliers. Ce sont des modèles car ils peuvent être généralement réutilisés pour des jobs similaires. Facilitant ainsi l'effort requis au démarrage d'un job. Comme l'on pourrait s'y attendre, il y a aussi des modèles d'utilisation courante qui peuvent être adoptés pour plusieurs cas d'utilisation différents, lesquels, lorsqu'ils sont correctement identifiés et implémentés, renforcent la base de code de votre projet, concentrent les efforts, et réduisent le code répétitif ou semblable. Aussi, commençons par là.
Voici 7 bonnes pratiques à prendre en considération :
Organisation des Workflow & Disposition
Il y a différentes manières de disposer vos composants dans le designer, et autant de manières de les lier entre eux. Ma préférence est clairement du 'Haut en Bas', puis de 'gauche à droite' où un flux situé à gauche représente généralement un flux en erreur, et un flux situé à droite et/ou vers le bas représente le chemin normal ou souhaité. Tâchez d’éviter les flux qui s'entrecroisent autant que possible, et, depuis la version v6.0.1, les jolis liens curvilignes se plient très bien à cette stratégie.
Je suis, pour ma part, particulièrement inconfortable avec les liens en zig-zag, ou les composants sont placés de 'gauche à droite en série', puis, une fois qu'ils ont atteint le bord droit de l'écran, retournent en bas à gauche pour recommencer; je trouve cette disposition gênante et plus difficile à maintenir, mais je comprends que l'on y cède (elle est facile à écrire). Utilisez cette représentation si vous le devez, mais il est possible qu'elle soit un signe que votre job en fasse plus que nécessaire ou ne soit pas correctement organisé.
Des jobs atomiques ~ Jobs parents/Fils
De grands jobs, avec beaucoup de composants, pour le dire simplement, sont difficiles à maintenir. Evitez ceci en les cassant en de plus petits jobs ou unités de travail à chaque fois que cela vous est possible. Puis exécutez-les comme des jobs fils depuis un job parent (en utilisant le composant tRunJob component) dont le but sera de gérer leur configuration et exécution. Ceci vous offrira aussi la possibilité de mieux gérer les erreurs et les tâches qui doivent suivre. N'oubliez pas qu'un job surchargé peut-être difficile à comprendre, difficile à débugger et à corriger et tout simplement impossible à maintenir. De simples, petits jobs qui ont un but clair arrivent toujours à remplir leur rôle, ils sont presque toujours faciles à debugger et à corriger, et leur maintenance, comparativement, est un jeu d'enfant.
Bien qu'il soit parfaitement acceptable de créer des hiérarchies de jobs parent/fils imbriqués, il y a quelques limitations pratiques à prendre en considération. Selon l'utilisation mémoire de votre job, des paramètres transmis, des problématiques de test et « debuggage », et des techniques de parallélisation (décrites plus bas), un bon job design ne devrait pas excéder 3 niveaux d'imbrication d'appels de tRunJob. Bien qu'il ne soit pas risqué d'aller plus en profondeur, je pense, avec quelques raisons, que 5 niveaux sont largement plus qu'assez pour n'importe quel type de cas d’utilisation.
Chosir entre le tRunJob et les Joblets
Les joblets n'existent pas dans la version Open Studio. Il s'agit en fait d'un regroupement de composants que vous pouvez utiliser un peu comme une macro instruction dans certains langages comme C/C++ ou encore un appel de fonction. C'est à dire qu'à la compilation le Joblet est remplacé par ses composants dans le job final. Tandis que le job est un sous-processus à part entière.
Points d'entrée et de sortie
Tous les jobs Talend ont besoin de commencer et de finir quelque part. Talend fournit 2 composants de base : tPreJob et tPostJob dont le but est de définir ce qui doit se passer en début et fin de l'exécution d'un job. Je les imagine comme l'« Initialiseur » et l'«Emballeur» final de mon code. Ils se comportent comme vous l'imaginez, le tPreJob en premier, ensuite le code proprement dit, et finalement le code du tPostJob terminera le programme. Notez que le tPostJob s'exécutera indifféremment des erreurs et interruptions volontaires (comme celle du composant tDie, ou de l'option « DieOnError » de certains composants) qui peuvent être rencontrées.
Toutefois l'option avancée « Sortir immédiatement de la JVM » du tDie arrêtera brutalement votre programme sans exécuter le tPostJob.
L'utilisation des composants tWarn et tDie doivent aussi être pris en considération comme points d'entrée et de sortie. Ils vous fournissent les moyens de contrôler la façon dont vos jobs se terminent. Ils offrent de plus des facilités pour la gestion des erreurs, les logs, et la récupération sur pannes.
Une des choses que j'apprécie pour ce pattern est d'utiliser le tPreJob pour initialiser les variables de contexte, créer les connexions, et « logger » des informations importantes. Quant-au tPostJob : je l'utilise pour fermer les connexions, faire un peu de nettoyage si requis et « logger » d'autres informations. C'est assez simple non ? L'avez-vous déjà fait ?
Gestion des erreurs & Logging
Ce point est très important, peut-être critique, et si vous créez correctement votre pattern, une mécanique hautement réutilisable pourra être mise en œuvre entre tous vos projets. Ce modèle vise à créer un joblet ‘logPROCESSING’ pour mettre au point un processeur de logs complet et maintenable qui puisse être inclus dans n'importe quel job, ET intégrant des ‘Codes de retour’ clairement définis qui vous apporteront, réutilisabilité et efficacité. De plus il est facile à écrire, facile à lire, et oui, il sera facile à maintenir. Je pense que lorsque vous aurez développé votre solution pour gérer les logs des jobs de votre projet, que vous aurez un large sourire que vous ne pourrez plus détacher de votre visage. Adaptez-le et adoptez-le! (Is this logPROCESSING joblet provided somewhere?)
Les versions récentes de Talend proposent un support pour Log4J et les serveurs de logs. Activez-le simplement via le menu « Editez les propriétés du projet/Log4j » et configurez le log stash server dans le TAC. Incorporer cette fonctionnalité dans vos jobs revêt assurément des bonnes pratiques !
Choisir entre les liens OnSubJobOK/ERROR et OnComponentOK/ERROR (& Run If)
Il peut être quelque peu difficile parfois pour un développeur Talend de faire la différence entre un lien ‘On SubJob’ et ‘On Component’. La différence entre les liens ‘OK’ et ‘ERROR’ est évidente. Aussi voyons en quoi ces ‘Déclencheurs de connexions’ diffèrent et comment ils affectent le flux des jobs.
Les ‘Déclencheurs de Connexions’ entre les composants définissent l'ordre d'exécution et du flux de données entre les sous-jobs. Les sous-jobs sont caractérisés par des composants liés entre eux par un flux de données. Plusieurs sous-jobs peuvent exister dans un job et les composants qu'ils contiennent sont délimités par un rectangle sur fond bleu (lequel peut-être désactivé via la barre d'outils).
Un lien ‘On Subjob OK/ERROR’ donnera la main au sous-job suivant une fois que tous les composants du sous-job courant auront terminé leur traitement. Ces liens ne sont disponibles que sur le premier composant de chaque sous-job. Un lien ‘On Component OK/ERROR’ passera la main au composant qu'il désigne dès que le composant source aura terminé son traitement. Un lien ‘Run If’ sera utile pour conditionner l'exécution du composant qu'il désigne doit être par une expression logique exprimable en Java.
Qu'est-ce qu'une boucle Loop ?
La ‘Boucle principale’ et la ‘Boucle secondaire’ sont importantes pour presque tous les design patterns de votre code. Elles correspondent aux endroits où les contrôles potentiels d'arrêt de l'exécution sont réalisés. La ‘Boucle principale’ est généralement représentée par le résultat du traitement le plus externe de votre flux de données, lequel, une fois terminé, marque la fin de votre job. Les ‘boucles secondaires’ sont elles-mêmes imbriquées dans une boucle de plus haut niveau et nécessitent de plus grands efforts pour s'assurer que le job se termine proprement. Je commence toujours par identifier la boucle principale et je m'assure d'avoir un tWarn et un tDie pour gérer ce composant. Je paramètre habituellement le tDie pour quitter immédiatement la JVM (mais n'oubliez pas que le tPostJob s'exécutera quand-même. Ces points de sortie utilisent la valeur ‘0’ en cas de succès et ‘1’ en cas d'erreur, mais préférez-y les règles que vous aurez établies dans votre guide de ‘Codes de retour’. Les ‘boucles secondaires’ (et autres composants critiques du flux) sont aussi sujettes à recevoir des composants tWarn et tDie (ou le tDie n'est pas configuré pour sortir immédiatement de la JVM).
La plupart de ces bonnes pratiques sont illustrées ci-dessous. Notez que j'ai utilisé des libellés significatifs pour les composants, même si je ne respecte pas très bien les règles de positionnement des composants. Quoiqu'il en soit, le résultat est facile à lire, maintenir et aura été facile à réaliser.
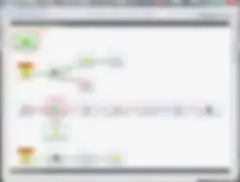
Conclusion
Bien ~ Il est peu probable que j'ai répondu à toutes vos questions sur les bonnes pratiques; et même certainement pas. Mais c'est un début! Nous avons abordé quelques éléments fondamentaux, fourni une direction à suivre et ciblé les limites du jeu. J'espère que cela vous aura été utile et génèrera en vous quelques révélations, Ô vénérables lecteurs.
Evidemment je dois écrire un autre blog (et certainement plusieurs) sur ce sujet pour en couvrir tous les aspects. Le prochain se concentrera sur des sujets à forte valeur ajoutée et plusieurs Use Cases que nous sommes tous à-même de rencontrer d'une manière ou d'une autre. De plus notre équipe « Customer Success Architecture » travaille sur quelques exemples de code Talend pour illustrer ces derniers. Ils seront disponibles dans le Talend Help Center prochainement pour les utilisateurs qui s'y sont inscrits. Restez attentifs pour ne pas manquer leur sortie.
Ressources connexes
5 Ways to Become A Data Integration Hero
Produits mentionnés

Plus d'articles connexes
- Big Data Health : la médecine de demain
- Qu'est-ce qu'un silo de données ?
- Qu’est-ce que l’extraction des données et comment la réaliser ?
- Modèles de conception des jobs Talend et bonnes pratiques : 4e partie
- Modèles de conception des jobs Talend et bonnes pratiques : 3e partie
- Qu'est-ce que la migration des données ?
- Qu’est-ce que le mappage des données ?
- Intégration de base de données – Présentation générale
- Tout savoir sur l'intégration de données
- Comprendre la migration des données : stratégie et bonnes pratiques
- Modèles de conception des jobs Talend et bonnes pratiques : 2e partie
- Guide sur Talend rédigé par un développeur d'Informatica PowerCenter : Partie 1