Modèles de conception des jobs Talend et bonnes pratiques : 3e partie
Mes précédents articles sur le sujet ont été très bien reçus. J'en remercie tous mes lecteurs !
Si vous êtes un nouveau lecteur et que vous ne connaissez pas mes précédents articles, je vous invite à commencer par les lire (Modèles de conception des jobs Talend et bonnes pratiques 1ère partie et 2e partie), puis à revenir à cette 3e partie. Tous les articles développent en effet le même thème et se suivent. The popularity of this series has in fact necessitated translations, and if you are so inclined, please read the new French versions (simply click on the French Flag). Thanks go out to Gaël Peglissco, ‘Chef de Projets’ of Makina Corpus for his persistence, patience, and professionalism in helping us get these translations crafted and published.
Avant de présenter plus de modèles de conception des jobs et de bonnes pratiques, je tenais à signaler que le contenu précédent avait été regroupé dans une présentation technique de 90 minutes. Cette présentation est intégrée dans les événements Talend Technical Boot Camps qui ont lieu un peu partout dans le monde à différentes dates. Consultez le site Web Talend pour rechercher un événement près de chez vous. J'aimerais beaucoup vous y rencontrer !
N'hésitez pas à me faire part de tous vos commentaires et questions, ou à donner votre avis sur le sujet si vous n'êtes pas d'accord avec moi : l'objectif principal de ces articles est d'étendre le débat à toute la communauté Talend. Souvenez-vous que je vous propose des directives et non des normes. Je peux donc légitimement espérer recevoir vos contributions et vos avis. Du moins je l'espère !
Développer le même thème
Vous devez maintenant avoir bien compris que j'accorde beaucoup d'importance aux « Directives de développement », que j'estime indispensables à la réussite de tout cycle de développement logiciel, mais je préfère le répéter : créer des directives de développement, les faire adopter par les équipes et inculquer progressivement une discipline, voilà le secret des résultats exceptionnels avec Talend. J'espère que vous êtes tous d'accord avec cela ! La conception des jobs Talend n'est pas forcément linéaire (et je ne fais pas référence aux nouvelles lignes courbes ici). Comprendre les bases des cas d'usage commerciaux, de la technologie et de la méthodologie vous offre plus de chances de réussite. Vous ne regretterez pas d'avoir pris le temps de rédiger des directives pour votre équipe, l'investissement en vaut la peine.
Les clients Talend sont souvent confrontés à des cas d'usage portant d'une manière ou d'une autre sur les processus d'intégration de données... Soit la compétence principale de Talend, le déplacement de données d'un point à un autre. Les flux de données sont très variés ; ce que nous en faisons et comment nous les manipulons est important. Tellement important que c'est devenu l'essence même de la quasi-totalité des jobs que nous créons. Alors, si le cas d'usage est le déplacement de données commerciales et que Talend répond aux besoins de technologie, quelle est la méthodologie ? Il s'agit bien sûr de la bonne pratique SDLC que nous avons déjà évoquée. Cependant, cette pratique n'est pas la seule réponse. Les méthodologies, en matière de données, incluent aussi la modélisation des données. C'est un sujet qui me passionne. J'ai été architecte de bases de données pendant plus de 25 ans et j'ai conçu un nombre incalculable de solutions de bases de données, j'ai donc pu constater dans la pratique que les systèmes de bases de données ont aussi un cycle de vie ! Quel que soit le schéma (fichiers non relationnels, EDI, OLTP, OLAP, STAR, Snowflake ou encore Data Vault), ignorer le processus allant de la création au retrait des données et des schémas correspondants est au mieux une faiblesse, et au pire une catastrophe !
Bien que les méthodologies de modélisation des données ne soient pas le sujet de cet article, je dois insister sur l'importance de l'adoption d'une conception et d'une utilisation structurées des données. Consultez ma série d'articles sur le Data Vault. Je prépare également des articles sur la modélisation des données. Vous devez me croire sur parole pour l'instant, mais le DDLC, Data Development Life Cycle ou Cycle de vie du développement des données, est une bonne pratique ! Pensez-y, et j'espère que vous me donnerez raison.
Plus de bonnes pratiques en matière de conception des jobs
Je vais maintenant vous présenter de nouvelles bonnes pratiques pour la conception des jobs Talend. Nous en avons détaillé 16 jusqu'à présent. En voici huit de plus (et je suis sûr que cette série comprendra un 4e article, car je ne parviendrai pas à vous dire tout ce que j'ai à dire dans celui-ci). Bonne découverte !
Huit bonnes pratiques supplémentaires
Routines de codage
Il arrive parfois que les composants Talend ne permettent pas de répondre à un besoin de programmation spécifique. Ce n'est pas grave, après tout Talend est un générateur de code Java. Il propose même des composants Java que vous pouvez placer sur votre toile pour incorporer du Java pur dans le flux de processus ou de données. Et si cela ne suffit pas ? Laissez-moi vous présenter ma solution préférée : les routines de codage. Il s'agit de méthodes Java que vous pouvez ajouter dans votre référentiel de projet, principalement des fonctions Java définies par l'utilisateur que vous codez et utilisez à différents endroits de votre job.
Talend fournit de nombreuses fonctions Java, que vous avez probablement déjà utilisées, par exemple :
- getCurrentDate()
- sequence(String seqName, int startValue, int step)
- ISNULL(object variable)
Les routines de codage vous permettent de faire de nombreuses choses dans le contexte global de votre job, projet et cas d'usage. La réutilisation du code est la clé ici : si vous créez une routine de codage permettant de simplifier un job de manière générique, vous êtes sur le bon chemin. Assurez-vous d'ajouter les commentaires nécessaires dans le texte d'aide (« helper ») lorsque vous définissez la fonction.

Schémas de référentiel
La section Métadonnées du référentiel de projet est l'endroit parfait pour créer des objets réutilisables (l'une de nos directives de développement importantes !). Les schémas de référentiel sont une méthode efficace de création d'objets réutilisables pour vos jobs. Cela inclut les éléments suivants :

- Délimité
- Positionnel
- Regex
- XML
- Excel
- JSON
- Schémas génériques : utilisés pour le mapping de différentes structures d'enregistrements
- Schémas WDSL : utilisés pour le mapping des structures de méthodes des services Web
- Schémas LDAP : utilisés pour le mapping d'une structure LDAP (des schémas LDIF sont également disponibles)
- UN/EDIFACT : utilisé pour le mapping de différentes structures de transactions EDI
Lorsque vous créez un schéma, vous lui attribuez un nom d'objet, un objectif et une description, ainsi qu'un nom d'objet de métadonnées référencé dans le code du job. Le nom par défaut est « metadata » (métadonnées). Prenez le temps de définir une convention de nommage pour ces objets, ou ils auront tous le même nom dans votre code. Pourquoi pas md_{nomdel'objet}, comme dans l'exemple ci-contre ?
Les schémas génériques sont très importants, car c'est là que vous créez les structures de données qui se concentrent sur vos besoins particuliers. Prenons une connexion à la base de données (dans le même exemple) qui a des schémas de tables ayant fait l'objet d'une rétro-ingénierie depuis une connexion à la base de données physique. La table « accounts » (comptes) a 12 colonnes, mais le schéma générique correspondant défini plus bas a 16 colonnes. Les colonnes en plus correspondent à des éléments de valeur ajoutés à la table « accounts » et sont utilisées dans un processus de flux de données au sein d'un job pour incorporer des données supplémentaires. À l'inverse, une table de base de données peut avoir plus de 100 colonnes, et 10 colonnes seulement peuvent être nécessaires pour un flux de données de job spécifique. Un schéma générique peut être défini pour que ces 10 colonnes envoient des requêtes à la table sur les colonnes correspondantes. Cette fonctionnalité peut se révéler très utile. Mon conseil : utilisez TRÈS SOUVENT les schémas génériques, sauf peut-être pour les structures à une colonne (celles-ci peuvent être simplement intégrées à la conception).
Notez que les autres types de connexion tels que SAP, Salesforce, NoSQL et les clusters Hadoop sont également tous compatibles avec la définition de schémas.
Log4J
Apache Log4J est disponible depuis la version 6.0.1 de Talend. Il offre un framework de journalisation Java robuste. Tous les composants Talend sont parfaitement compatibles avec les services Log4J qui améliorent la méthodologie de gestion des erreurs que j'évoquais dans mes articles précédents. J'espère que vous tenez désormais tous compte de ces bonnes pratiques dans vos projets. Il ne vous reste plus qu'à les améliorer avec Log4J !
Log4J doit être activé pour que vous puissiez l'utiliser. Activez-le depuis les paramètres du projet. Depuis les paramètres, vous pouvez également adapter les directives de journalisation données à vos équipes afin de définir un mode d'envoi des messages cohérent pour la Console (stderr/stdout) et les appenders LogStash. Définir ici les appenders de manière centralisée vous permet de facilement incorporer des fonctionnalités Log4J dans vos jobs Talend. Notez que les valeurs de niveau dans la syntaxe Log4J correspondent aux priorités que vous connaissez déjà : INFO/WARN/ERROR/FATAL (Info/Avertissement/Erreur/Fatal).
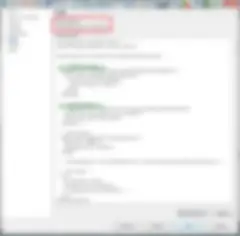
Dans Talend Administration Center (TAC), lorsque vous créez une tâche pour exécuter un job, vous pouvez également choisir le niveau de priorité que Log4J utilisera pour la journalisation. Assurez-vous de sélectionner le bon niveau pour les différents environnements DEV/TEST et PROD. La bonne pratique consiste à sélectionner INFO pour DEV/TEST, WARN pour UAT et ERROR pour PROD. Tous les niveaux supérieurs au niveau sélectionné sont également inclus.

Utilisé avec les composants tWarn et tDie ainsi que le nouveau serveur de logs, Log4J peut grandement améliorer le monitoring et le suivi de l'exécution des jobs. Utilisez cette fonctionnalité pour définir des directives de développement pour votre équipe.
Monitoring de l’activité des Jobs
Talend propose un module complémentaire intégré permettant un monitoring amélioré de l'exécution des jobs, qui consolide les informations collectées à propos du traitement dans une base de données. Son interface graphique est accessible depuis Studio et TAC. Il aide les développeurs et administrateurs à comprendre les interactions entre composants et jobs, prévient les défauts inattendus et aide à la prise de décisions importantes concernant la gestion du système. Cette fonctionnalité n'est pas incluse par défaut, vous devez installer la base de données et l'application Web AMC. Le Guide utilisateur Activity Monitoring Console Talend inclut toutes les informations dont vous avez besoin pour installer le composant AMC, je ne vous embêterai donc pas avec ça. Concentrons-nous plutôt sur les bonnes pratiques pour l'utiliser.

La base de données AMC contient trois tables :
- tLogCatcher : capture les données envoyées par les exceptions Java ou les composants tWarn/tDie
- tStatCatcher : capture les données envoyées par l'option Statistiques du tStatCatcher des composants individuels
- tFlowMeterCatcher : capture les données envoyées par le composant tFlowMeter
Ces tables enregistrent les données pour l'interface d'AMC, qui permet une visualisation complète de l'activité d'un job basée sur ces données. Choisissez bien vos paramètres de priorité pour la journalisation dans l'onglet des préférences du projet, et tenez compte de toute restriction des données définie pour l'exécution des jobs dans chaque environnement DEV/TEST/PROD. Utilisez la vue Main Chart (Graphique principal) pour identifier et analyser les goulots d'étranglement dans le job avant tout passage dans un environnement PROD. Consultez la vue Error Report (Rapport d'erreur) pour analyser la proportion d'erreurs sur une période donnée.

Ces tables peuvent également être utilisées à d'autres fins. Puisqu'elles sont après tout des tables dans une base de données, des requêtes SQL peuvent être utilisées pour en extraire des informations utiles. Avec des outils de script, il est possible de créer des requêtes et des notifications automatisées répondant à certaines conditions journalisées dans la base de données AMC. En utilisant une technique de code de retour efficace, comme décrit dans le premier article de cette série, ces requêtes peuvent automatiquement effectuer des opérations programmées très utiles.
Points de validation de reprise
L'exécution de l'un de vos jobs est très longue ? Ce job comporte peut-être plusieurs étapes critiques, et si l'une des étapes échoue, relancer l'exécution depuis le départ peut s'avérer compliqué. Il serait appréciable de pouvoir réduire le temps et les efforts nécessaires pour redémarrer le job à un point spécifique du flux, juste avant que l'erreur ne survienne. TAC propose justement une fonctionnalité spéciale de restauration de l'exécution lorsqu'un job rencontre une erreur. Les jobs qui intègrent des points de validation de reprise (placés de manière stratégique) peuvent reprendre l'exécution sans repartir du début et poursuivre le traitement.

En cas d'échec, utilisez l'onglet « Error Recovery Management » (Gestion des reprises sur erreur) pour déterminer l'erreur et relancer le traitement du job.

Joblets
Nous avons déjà défini ce qu'est un joblet, un code de job réutilisable qui peut être inclus dans un ou plusieurs jobs selon les besoins, mais allons plus loin. Il n'existe pas beaucoup de cas d'usage pour les joblets, mais si vous en trouvez un, alors utilisez le joblet, c'est sûrement un outil précieux ! Les joblets peuvent être construits et utilisés de différentes manières. Voyons cela en détail.
Lorsque vous créez un joblet, les composants Input/Output (Entrée/Sortie) sont automatiquement ajoutés à votre toile. Ce démarrage simplifié vous permet d'assigner les schémas entrant et sortant du workflow du job à l'aide du joblet. Un joblet est généralement utilisé pour permettre le passage des données ; ce que vous faites à l'intérieur est de votre ressort. Dans l'exemple ci-dessous, une ligne est introduite, une table de base de données est mise à jour, la ligne est consignée dans stdout, puis cette même ligne non modifiée (dans ce cas) est extraite.

Un cas d'usage spécifique pourrait être de supprimer l'un des composants Input (Entrée) ou Output (Sortie), ou les deux, pour permettre un traitement du flux de données ou du processus pour des cas particuliers. Dans l'exemple ci-dessous, aucun élément n'entre ou ne sort du joblet. Un composant tLogCatcher surveille diverses exceptions sélectionnées pour un traitement ultérieur (nous avons déjà vu ce cas lors de l'étude des bonnes pratiques pour la gestion des erreurs).
Les joblets peuvent ainsi considérablement améliorer la réutilisabilité du code. Placez ces outils précieux dans un projet de référence pour étendre leur utilisation à de nombreux projets. Ils vous seront très utiles pour atteindre vos objectifs.
Cas de tests de composants
Si vous utilisez une version antérieure à la v6.0.1 de Talend, vous pouvez ignorer ce passage... Ou mieux encore, vous pouvez mettre à niveau le logiciel ! L'une de mes nouvelles fonctionnalités préférées est la possibilité de créer des cas de tests. Il ne s'agit pas exactement de tests unitaires, mais plutôt de tests de composants, des jobs reliés au sein d'un job parent, et plus spécifiquement du composant testé. Certains composants ne sont pas compatibles avec les cas de tests, seuls ceux faisant entrer et sortir un flux de données le sont.
Pour créer un cas de test de composant, faites simplement un clic droit sur le composant sélectionné et cliquez sur « Create test case » (Créer un cas de test). Un nouveau job est alors généré et s'ouvre en présentant un modèle fonctionnel pour le cas de test. Le composant testé est disponible ici avec les composants INPUT et OUTPUT intégrés liés dans un flux de données, qui lit simplement un fichier Input File (Fichier d'entrée), traite les données de ce fichier et transmet les enregistrements dans le composant testé, qui fait ce pourquoi il a été créé puis écrit les résultats de sortie dans un nouveau fichier Result File (Fichier de résultats). Ce fichier est ensuite comparé avec les résultats attendus du fichier Reference File (Fichier de référence). La réussite ou l'échec de cette comparaison est déterminé par la correspondance ou non des résultats. C'est simple, non ? Voyons cela en détail.
Voici un exemple de job que nous avons déjà étudié. Un composant tJavaFlex manipule le flux de données, le transmettant en aval pour la suite du traitement.

Le job de cas de test ci-dessous a été créé : aucune modification n'est requise (même si j'ai nettoyé un peu la toile).
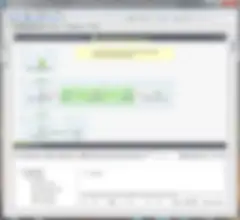
Il est important de savoir que, bien que vous puissiez modifier le code du job de cas de test, vous ne devriez modifier le composant testé que dans le job parent. Disons par exemple que le schéma doive être modifié. Modifiez-le dans le job parent (ou le référentiel) et le cas de test héritera de la modification. Ils sont connectés et couplés par le schéma.
Notez que lorsqu'une instance de cas de test est créée, plusieurs fichiers input et reference peuvent être créés et testés dans le même job de cas de test. Cela permet de tester des données correctes ou incorrectes, petites ou volumineuses, ou encore spécialisées. Je vous recommande ici de bien réfléchir non seulement à ce que vous testez, mais également aux données de test que vous utilisez.
Enfin, lorsque le référentiel d'artefacts Nexus est utilisé et que des jobs de cas de tests y sont stockés avec leurs jobs parents, il est possible d'utiliser des outils tels que Jenkins pour automatiser l'exécution de ces tests, et ainsi déterminer automatiquement si un job est prêt à être utilisé dans l'environnement suivant.
Itérations des flux de données
En développant du code dans Talend, vous avez sûrement déjà remarqué que vous liez les composants à l'aide d'un processus trigger (déclencheur) ou d'un connecteur de flux de données row (ligne). En cliquant avec le bouton droit sur le composant de départ et en connectant le lien « line » (ligne) au composant suivant, vous établissez cette liaison. Les liens de flux de processus sont OnSubJobOk/ERROR, OnComponentOK/ERROR ou RunIF. Nous en avons déjà parlé dans mon article précédent. Les liens de flux de données, lorsqu'ils sont connectés, sont nommés de manière dynamique row{x}, où x (un chiffre) est assigné dynamiquement par Talend pour créer un nom d'objet/de ligne unique. Le nom de ces liens de flux de données peut bien sûr être personnalisé (selon une bonne pratique de convention de nommage). Établir ce lien permet essentiellement de mapper le schéma de données d'un composant à l'autre et représente le pipeline dans lequel les données passent. Au moment de l'exécution, l'ensemble de données transitant via cette liaison est souvent appelé « dataset ». Selon les composants en aval, le dataset complet est traité de bout en bout au sein du sous-job encapsulé.
Certains datasets ne peuvent pas être ainsi traités en une seule fois, et le flux de données doit parfois être contrôlé directement. Ce contrôle est possible grâce au traitement row-by-row (ligne par ligne), ou itérations. Examinez ce code factice sans aucun sens :

Remarquez les composants tIterateToFlow et tFlowToIterate. Ces composants spécialisés vous permettent de placer un contrôle sur le traitement du flux de données en autorisant les itérations sur les datasets, ligne par ligne. Ce traitement basé sur une liste peut être très utile parfois. Soyez prudent cependant : dans bien des cas, lorsque vous séparez un flux de données en itérations ligne par ligne, vous devrez le reconsolider dans un dataset complet avant de pouvoir poursuivre le traitement (comme tMap par exemple). Certains composants exigent en effet un flux de dataset de type row et ne peuvent pas prendre en charge un flux itératif. Notez également que les composants t{DB}Input offrent à la fois une option Main et Iterate (Itérer un flux de données) dans le menu Row.
Examinez ces exemples de scénario : Transforming data flow to a list (Transformer un flux de données en liste) et Transforming a list of files as a data flow (Transformer une liste de fichiers en flux de données), disponibles dans le Centre d'aide Talend et le guide Talend Components Reference Guide. Ils expliquent précisément comment utiliser cette fonctionnalité. Utilisez-la selon vos besoins, et assurez-vous d'ajouter des libellés significatifs pour décrire vos objectifs.
Conclusion
Voilà une somme d'informations à assimiler ! Nous avons presque terminé. Dans le 4e article de cette série, j'aborderai les derniers modèles de conception des jobs et bonnes pratiques assurant les bases d'un code Talend correct. J'ai également promis d'évoquer des exemples de cas d'usage, et je le ferai. Garder toutes ces bonnes pratiques à l'esprit vous sera bien utile lorsque nous commencerons à parler de leurs applications abstraites. Comme toujours, j'attends avec impatience vos commentaires, questions et avis. Bonsai!

Plus d'articles connexes
- Big Data Health : la médecine de demain
- Qu'est-ce qu'un silo de données ?
- Qu’est-ce que l’extraction des données et comment la réaliser ?
- Modèles de conception des jobs Talend et bonnes pratiques : 4e partie
- Qu'est-ce que la migration des données ?
- Qu’est-ce que le mappage des données ?
- Intégration de base de données – Présentation générale
- Tout savoir sur l'intégration de données
- Comprendre la migration des données : stratégie et bonnes pratiques
- Modèles de conception des jobs Talend et bonnes pratiques : 2e partie
- Talend “Modèles de Conception de Job” et Bonnes Pratiques : 1e partie
- Guide sur Talend rédigé par un développeur d'Informatica PowerCenter : Partie 1