Progettazione di modelli di dati e best practice: Parte 2
Che cos'è un modello di dati? Chi è uno sviluppatore Talend come me, ha quotidianamente a che fare con modelli di dati e crede di sapere di cosa si tratta:
- Una definizione strutturale dei dati di un sistema aziendale
- Una rappresentazione grafica dei dati di business
- Una base dati sui cui realizzare soluzioni per l'azienda
Tutte queste affermazioni possono essere vere, tuttavia, lasciatemi affermare che in realtà si tratta di definizioni non pertinenti o secondarie, in quanto, individualmente, non vanno alla radice della questione o non definiscono il vero scopo di un modello di dati.
Che cos'è dunque un modello di dati? Credo che si tratti di tante cose diverse e, allo stesso tempo, di una specifica cosa. Per me, un modello di dati è la base strutturale, rappresentata mediante una caratterizzazione grafica ben definita, di un sistema informatico aziendale. Cosa ne pensate? Sembrerebbe esattamente quanto affermato in precedenza, no? In realtà, non proprio. Questa definizione include tutti gli elementi delle affermazioni precedenti, convogliandoli verso un'unica finalità; ovvero l'identificazione strutturale di informazioni su uno specifico caso d'uso aziendale, e non semplicemente dei suoi dati.
Nella Parte 1 di questa serie di blog, ho cercato di condensare cinquant'anni di storia della modellazione dei dati in 4 brevi paragrafi. Sicuramente ho tralasciato qualcosa, tuttavia, ritengo che comprendere come siamo arrivati al punto in cui siamo in termini di modellazione dei dati è il risultato di lezioni apprese e miglioramenti ottenuti dai nostri predecessori. Oggi, la maggior parte delle aziende impiega i modelli di dati per convalidare requisiti, un effettivo valore di business, ma spesso mi chiedo se sanno farlo nel modo giusto. In molti casi, l'illusione di disporre di un modello di dati valido viene data per scontata semplicemente perché si presume che ne esista soltanto uno, senza sapere o verificare se ciò corrisponde al vero.
In qualità di data architect e database designer professionista, ho visto così tanti pessimi modelli di dati da essermi quasi convinto che la maggior parte di essi è probabilmente, in qualche misura, sbagliata. Ne ho visti anche di buoni, però. In ogni caso, come si fa a capire se un modello di dati è valido o meno? Ma perché ci dovrebbe importare? Fintanto che i dati entrano ed escono, non è sufficiente? La risposta è un fragoroso NO! I modelli di dati devono essere buoni o ottimi per assicurare l'efficacia dei sistemi aziendali che vengono eseguiti rispetto ad essi e/o in collaborazione con essi. Il modello di dati è l'essenza del business, di conseguenza deve essere completo, inattaccabile e flessibile.
I motivi della necessità di disporre di un buon modello di dati sono pertanto chiari. Basterà iniziare a inserire e ad estrarre dati mediante strumenti ETL/ELT come Talend Studio, perché diventi ancora più evidente (alla maggior parte di noi). Credo che un modello di dati sia una delle tre componenti tecniche essenziali di un progetto software. Le altre due sono il codice dell'applicazione e l'interfaccia utente.
Avrete senz'altro sentito parlare, nella Parte 1 di questo blog, della metodologia del ciclo vitale di sviluppo del database (DDLC), che applico in ogni modello di dati che progetto. Questa metodologia mi è stata molto utile e la consiglio vivamente a tutti i team di sviluppo di database che si rispettino. La comprensione e l'utilizzo di questa procedura possono semplificare, automatizzare e migliorare qualsiasi attività di implementazione e manutenzione di un modello di dati. Tuttavia, ci sono ancora diversi aspetti di questo processo che dobbiamo analizzare. Vi illustrerò alcune best practice aggiuntive che possono aiutarvi a definire un modello di dati affidabile, flessibile e accurato per il vostro business.
Best practice per la creazione di modelli di dati
Molti modelli di dati vengono progettati in base a una procedura che prevede la creazione prima di un modello logico, quindi di uno fisico. Generalmente, i modelli logici descrivono entità e attributi, così come le relazioni che li legano, fornendo una rappresentazione chiara della finalità di business dei dati. I modelli fisici implementano quindi i modelli logici, come tabelle, colonne, tipi di dati e indici, insieme a regole concise sull'integrità dei dati. Tali regole definiscono le chiavi primarie ed esterne, così come i valori predefiniti. Inoltre, è possibile definire viste, trigger e stored procedure per supportare l'implementazione in base alle necessità. Il modello fisico definisce anche l'allocazione dello spazio di archiviazione su disco, sulla base di specifiche opzioni di configurazione fornite dalla maggior parte dei sistemi host (come Oracle, MS SQL Server, MySQL, ecc.).
Semplice, no? Ciononostante, molte volte sono stato coinvolto in accesi dibattiti sulla differenza tra un modello logico e un modello concettuale. Molti sostengono che si tratti della stessa cosa, in quanto entrambi presentano entità e attributi dei dati di business. Sono in totale disaccordo! Il modello concettuale vuole fornire contesto finalizzato a una comprensione dei dati da un punto di vista aziendale, non tecnico. Se tutte le parti in causa sono in grado di comprendere un modello concettuale, molti hanno difficoltà a distinguere entità e attributi. Secondo me, il modello concettuale, se concepito nel modo giusto, è il MIGLIORE strumento di comunicazione dei dati di business a tutte le parti in causa. Per quanto mi riguarda, preferisco utilizzare alcuni aspetti del linguaggio UML (Unified Modeling Language ) per tracciare un diagramma di modello concettuale, mantenendolo semplice, senza addentrarmi troppo nei dettagli. Me ne occuperò quando vi illustrerò i modelli logico e fisico, in cui i dettagli sono essenziali e rifiniti.
Nel mondo aziendale, con il suo elevato numero di sistemi di applicazioni, la modellazione dei dati comporta un ulteriore livello di preoccupazione. Mi sono accorto che i modelli concettuali, logici e fisici non sono sufficienti. Introduzione: il modello di dati olistico; o la mia personale versione!
L'intento del modello di dati olistico è identificare ed estrarre silo di dati all'interno di un ambiente aziendale, descrivendo ciò che esiste o che è necessario, come i dati sono in relazione tra loro e come organizzarli per poterli utilizzare al meglio.
I quattro livelli di elaborazione della modellazione dei dati
Considerando il potenziale dei quattro diversi tipi di modelli di dati all'interno di un ambiente aziendale, propongo la seguente procedura di modellazione dei dati a più "livelli", dall'alto verso il basso, per la definizione di un modello, il perfezionamento della sua comprensione e specifiche funzioni di progettazione. I ruoli chiave di ciascun livello identificano chi viene coinvolto nel processo e in quale fase.
Modello di dati olistico:
Il livello olistico rappresenta un panorama astratto di silo di dati all'interno di un'azienda. Questo modello di dati crea l'opportunità di stabilire una governance dei dati diffusa a livello aziendale, agevolando di conseguenza una migliore comprensione di tutte le relazioni tra i dati aziendali. Sono inclusi dati provenienti da qualsiasi applicazione, sia interna che esterna. Per descrivere graficamente il modello di dati olistico uso un diagramma a bolle Ecco come funziona:
Diagrammi a bolle – Silo di dati
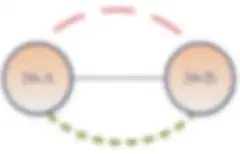

Talvolta una bolla è inclusa in una bolla più grande. Queste bolle più grandi indicano che esiste (o dovrebbe esistere) un'ontologia responsabile dell'organizzazione di una tassonomia specifica per tale silo di dati. Le ontologie e i metadati delle relative tassonomie offrono utili mappature in relazione al silo che contengono. Tali mappature sono molto utili per rendere i dati altamente ricercabili e dovrebbero essere identificate in questo livello.
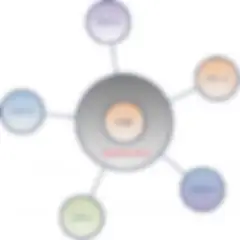
Ecco un esempio di come dovrebbe apparire un modello di dati olistico completamente definito. Provate a stamparlo in un formato grande e ad appenderlo a una parete. Il diagramma può suscitare conversazioni produttive e diventare una risorsa efficace e preziosa per l'azienda.
Modello di dati concettuale:

Architettura delle informazioni UML
Ciascun oggetto elemento incorpora una porzione particolare di un silo di dati e di linee di collegamento (chiamate anche link) che definiscono specifiche relazioni tra due elementi (ancora una volta, due soltanto). Per agevolare la comprensione dell'oggetto e della sua finalità vengono definiti degli elementi particolari (chiamati caratteristiche). Essi possono essere:
- Protetti (i valori sono predeterminati)
- Pubblici (i valori sono modificabili)
- Privati (i valori hanno un utilizzo limitato)
Se gli oggetti elemento sono connessi direttamente gli uni agli altri, si presume che abbiano delle "associazioni", indicate da un collegamento VERDE continuo e da etichette significative. Tali associazioni, utilizzando il simbolo del diamante sull'elemento padre, presentano relazioni che possono essere:
- Semplici (nessun diamante)
- Condivise (diamante aperto)
- Composite (diamante solido)
Un elemento figlio può anche essere "navigabile", in tal caso viene utilizzato il simbolo della freccia, ulteriormente identificato mediante una cardinalità relazionale (0.* = da zero a molti, ecc.).
Gli oggetti elemento possono presentare anche delle "generalizzazioni", il che significa che l'istanza di un oggetto può avere alcune caratteristiche e/o relazioni particolari o uniche. In questa rappresentazione, l'oggetto è più simile alla sotto-categoria di un elemento padre e include tutte le sue caratteristiche, PIÙ ulteriori eventuali caratteristiche univoche coinvolte. L'elemento sotto-categoria viene perfezionato nel nome e nella rappresentazione per fornire un miglioramento comprensibile rispetto al silo di dati astratto del modello olistico. Le generalizzazioni connesse agli oggetti elemento sono indicate mediante collegamenti BLU continui e presentano una freccia chiusa associata all'oggetto padre; non è richiesta alcuna etichetta.
Le connessioni tra sotto-categorie definiscono ulteriormente relazioni utili alla comprensione del modello di dati concettuale rappresentato. Le sotto-categorie generalizzate collegate ad altre sotto-categorie generalizzate dello stesso oggetto padre dovrebbero presentare "associazioni" indicate mediante collegamenti VERDI continui ed etichette appropriate. Tali relazioni possono facoltativamente essere "navigabili", in tal caso viene utilizzato il simbolo della freccia aperta, e ulteriormente identificate mediante una cardinalità relazionale (0.* = da zero a molti, ecc.).
Per completare il diagramma UML, gli elementi possono presentare associazioni in relazione con se stesse; si tratta di caratteristiche specifiche che estendono la definizione di un oggetto padre e/o di "associazioni" tra caratteristiche specifiche. Le specifiche estensioni non rappresentano una categoria o una generalizzazione, ma identificano caratteristiche pertinenti che vengono chiamate in causa per favorire una migliore comprensione del silo di dati astratto. La connessione di specifiche caratteristiche a un elemento viene indicata mediante un collegamento ROSSO continuo e un'etichetta appropriata. Inoltre, le caratteristiche di un elemento possono essere connesse ad altre caratteristiche elemento dello stesso oggetto padre e indicate mediante collegamenti VERDI continui, simili a quelli delle generalizzazioni correlate. Tali relazioni possono anche essere "navigabili", in tal caso viene facoltativamente utilizzato il simbolo della freccia aperta, e ulteriormente identificate mediante una cardinalità relazionale (0.* = da zero a molti, ecc.).
Il modello di dati concettuale descrive particolari elementi di dati mediante una metafora basata sulle categorie, e viene illustrato al meglio utilizzando il linguaggio UML, che riesce a spiegare più nel dettaglio i silo di dati astratti del modello olistico. L'obiettivo è definire, perfezionare e mitigare i dati di business, sempre senza considerare applicazioni, regole di implementazione o dettagli tecnici, e di includere dettagli tralasciati dal modello olistico.
Anche in questo caso, provate a stampare il modello in un formato grande; potrete notare che la sua rappresentazione fornisce un'interfaccia comune per la compilazione di codice delle applicazioni senza che siano necessari i modelli di dati logici o fisici che vedremo di seguito. Tale vantaggio può anche costituire un punto di convalida prima della creazione dei successivi modelli di dati. La convalida del modello UML in collaborazione con il team di ingegneri software e le parti interessate è una tappa fondamentale del processo di modellazione dei dati. Ecco un esempio di come dovrebbe apparire una porzione di modello di dati concettuale.
Come si può notare, il modello presenta dei "sotto elementi" che definiscono particolari aspetti dell'"elemento principale", chiarendo caratteristiche esclusive e ricorrenti.
Modello di dati logico:
Il livello logico rappresenta una struttura astratta di informazioni semantiche organizzate in termini di entità di dominio (oggetti dati logici), loro attributi e specifiche relazioni tra loro. Questo modello di dati, derivato dagli oggetti elemento del modello concettuale, definisce dettagli pertinenti (chiavi/attributi), oltre alle relazioni tra le entità, senza tenere conto di specifiche tecnologie di storage host. Le entità possono rappresentare un singolo elemento, parte di un elemento o più elementi, in base alle necessità, per racchiudere strutture di dati idonee. Il modello di dati logico racchiude le entità strutturali e i set di record identificati nel modello concettuale, con in più specifici attributi per agevolare una migliore comprensione dei dati coinvolti. Ecco come funziona:
Modello E-R
I modelli E-R, o Entity Relationship Diagram, descrivono entità univocamente identificabili, in grado di esistere in modo indipendente, che a loro volta richiedono una serie minima di attributi univocamente identificabili denominati chiavi primarie (PK). Se un'entità figlio è collegata a un'entità padre, è necessario fare rispettare l'integrità referenziale dei dati mediante l'uso nell'entità figlio di un attributo identificativo corrispondente agli attributi della chiave primaria dell'entità padre, denominato chiave esterna (FK). Ma tutto questo lo sapete già.
Se appropriato, le entità possono essere collegate tra loro a dimostrazione della natura di un set di record o della relazione di cardinalità tra due o più entità. Le entità con collegamenti possono utilizzare la tecnica denominata "crow’s foot notation" (notazione a zampa di gallina), ampiamente adottata nei modelli E-R. Indicata da collegamenti BLU continui, la "crow’s foot notation" appropriata su entrambi i lati dovrebbe anche includere un'etichetta che descriva il set di record che rappresenta. Questi collegamenti tra entità presentano una cardinalità specifica, che spiega il numero di record consentito per un set di record. Queste "notation" possono specificare: zero, una o molte righe o una qualsiasi combinazione obbligatoria.
La cardinalità presenta solo due regole: il numero minimo e massimo di righe per ciascuna entità che può partecipare a una relazione, dove la "notation" più prossima all'entità corrisponde al numero massimo. La specifica cardinalità di un set di record indica inoltre se la relazione è facoltativa o obbligatoria, aiutando nella progettazione del modello di dati fisico.
Un modello E-R può supportare collegamenti a più entità, inclusi collegamenti in relazione con se stessi. Inoltre, le entità non dovrebbero essere confuse con le mappe, nonostante vengano spesso mappate direttamente a tabelle di un modello di dati fisico (come vedremo di seguito). Le entità logiche invece sono astrazioni strutturali che puntano a rappresentare in modo semplificato il modello di dati concettuale.
Il modello di dati logico presenta l'astrazione semantica del modello di dati concettuale, fornendo dettagli utili alla progettazione di un modello di dati fisico. Un simile vantaggio può inoltre essere d'aiuto agli application services engineer, così come ai database engineer, in quanto fornisce una base per la comprensione non solo della struttura astratta dei dati, ma anche dei requisiti per le loro transazioni. Ecco un esempio di come dovrebbe apparire una porzione di modello di dati logico.
Possiamo notare alcune cose. Ho usato i colori per rappresentare diverse aree funzionali che possono essere ricondotte ai modelli concettuale e olistico. Ho anche incorporato una relazione "virtuale" tra ENTITY_D ed ENTITY_C (rappresentata da un collegamento GRIGIO CHIARO). Questo indica che esiste una relazione logica, tuttavia il costrutto tra queste due entità più l'ENTITY_B rappresenta un "riferimento circolare", ovvero qualcosa da evitare assolutamente nel modello fisico. Si noti inoltre la presenza di alcuni attributi che definiscono un array di valori. Nel modello logico questo è possibile, in quanto consente di snellire e semplificare il modello; ricordate di normalizzare tali attributi nel modello fisico.
Modello di dati fisico:
Il livello fisico rappresenta una combinazione di artefatti di sistemi host (oggetti dati fisici) derivati da un modello di dati logico, associati alla relativa configurazione di storage richiesta. Questo modello di dati incorpora tabelle, colonne, tipi di dati, chiavi, vincoli, autorizzazioni, indici, viste e dettagli sui parametri di allocazione disponibili nel data store (per maggiori informazioni sui data store, potete consultare il mio blog Beyond the Data Vault (Oltre il Data Vault)). Tali artefatti host rappresentano l'effettivo modello di dati a partire dal quale vengono create le applicazioni software. Il modello di dati fisico racchiude tutti questi artefatti derivati da entità e attributi definiti nel modello di dati logico, per consentire in ultima analisi a un'applicazione di accedere per memorizzare e recuperare i dati effettivi. Ecco come funziona:
Modello SDM
Un modello SDM (Schema Design Model), o modello fisico, definisce gli specifici oggetti coinvolti in un sistema di database. Darò per scontato che la maggior parte dei miei lettori conosca meglio questo modello di dati rispetto ai tre precedenti, quindi eviterò di descriverne la composizione. Preferisco chiamare questo modello SDM, per evitare che venga confuso con il più utilizzato modello E-R, che NON è un modello di dati fisico. Al contrario, il modello SDM fornisce un punto di riferimento tecnico spesso registrato sia mediante uno schema grafico che un documento detto "dizionario dei dati". Fornendo riferimenti fondamentali e dettagliati per ogni oggetto database implementato nel modello SDM, questo documento dovrebbe incorporarne anche scopo, regole di integrità referenziale e altre importanti informazioni relative a qualunque condotta prevista. Ecco una valida struttura da me impiegata:
- Nome oggetto e definizione (Tabelle/viste)
- Nome file di creazione/modifica oggetto SQL
- Ambito aziendale e utilizzo funzionale
- Versione/livello di integrità
- Colonne/tipi di dati/dimensioni
- Supporto dei valori Null
- Valori predefiniti
- Chiavi primarie
- Chiave esterne
- Chiavi naturali aziendali
- Vincoli univoci
- Vincoli di verifica
- Indici univoci e non univoci (raggruppati e non raggruppati)
- Flussi di controllo (quando è prevista una maggiore complessità di progettazione/uso)
- Commenti utili
- Cronologia delle modifiche
In un dizionario dati SDM gli oggetti vengono citati in ordine alfabetico, in base al nome, per semplicità d'uso. Dal momento che la maggior parte dei dati fisici è altamente normalizzata (avete forse letto la Parte 1 di questa serie di blog), è necessario chiamare in causa regole di integrità referenziale per ciascuna tabella. Nella mia esperienza, ho visto gestire queste regole in tanti modi diversi, in particolare durante l'esecuzione di script di oggetti SQL rispetto a uno schema esistente. Il modo più semplice consiste nel disattivare le verifiche di integrità, eseguire gli script quindi riattivare le verifiche; funziona, ma non sono un sostenitore di questo metodo in quanto è soggetto a errori.
Io preferisco invece dedicare un po' di tempo alla comprensione dei particolari riferimenti alle varie tabelle per poi assegnare un livello di integrità a ciascuna di esse. Il "livello di integrità" di una tabella identifica l'ordinamento gerarchico della relazione padre/figlio della tabella. In breve, il "livello di integrità" di una tabella si basa su un qualsiasi riferimento di chiave esterna alle tabelle padre. Ad esempio:
- Una tabella che non presenta tabelle padre è una tabella L0 - o di livello 0 (livello massimo)
- Una tabella che presenta almeno una tabella padre è una tabella L1 - o di livello 1
- Una tabella che presenta almeno una tabella padre, ma tale tabella padre presenta una tabella padre L0 è una tabella L2 - o di livello 2
- Una tabella con più tabelle padre che presentano a loro volta tabelle padre di vari livelli utilizza il livello più basso, ovvero il livello +1
- Ad esempio: se la tabella padre A è L0 e la tabella padre B è L1, la tabella figlio è L2 oppure: se la tabella padre A è L1 e la tabella padre B è L4, la tabella figlio è L5
- e così via
NOTA: L0 corrisponde al livello massimo in quanto non prevede tabelle padre; il livello minimo è invece determinato dal modello di dati fisico. Questo metodo elimina inoltre la possibilità di creare riferimenti circolari (una pessima pratica per la creazione di modelli di dati, a mio parare).
Il modello di dati fisico è il solo modello che viene effettivamente implementato. Per questa implementazione, preferisco usare script per la creazione di oggetti SQL o SOCS. Utilizzando questo metodo ho potuto constatare che il ciclo vitale di sviluppo del database per un qualsiasi modello di dati fisico può essere estrapolato come processo indipendente, cosa assolutamente auspicabile ma difficile da realizzare. L'idea è quella di creare un file SOCS per ogni oggetto database primario (tabella, vista, trigger o stored procedure). Questi script contengono verifiche intelligenti che consentono di determinare quali istruzioni SQL applicare (trascina, crea, modifica, ecc.) e possono, tramite gli switch e gli argomenti trasmessi, contribuire al ciclo vitale illustrato nel mio blog precedente, ovvero:
- INSTALLAZIONE iniziale – basata sulla versione corrente dello schema
- Applicazione di un UPGRADE – rilascio/creazione/alterazione di oggetti dB per l'aggiornamento di una versione alla successiva
- MIGRAZIONE dei dati – quando un upgrade ha conseguenze "devastanti" (come la separazione di tabelle o della piattaforma)
Questi file SOCS incorporano anche delle best practice, che includono (le vostre possono essere differenti):
- Convenzioni di denominazione coerente
- Nomi delle tabelle interamente in MAIUSCOLO
- Nomi delle colonne interamente in MINUSCOLO
- Nomi delle viste interamente a cammello (CamelCase)
- Nomi dei file SOCS che incorporano il nome oggetto
- Chiavi primarie a colonna singola che utilizzano valori interi delle dimensioni appropriate
- Eliminazione di dati ridondanti/duplicati (tuple)
- Eliminazione di tutti i riferimenti circolari (nel caso in cui si verifichino relazioni padre > figlio > padre)
- Un singolo file SOCS per oggetto
- File SOCS contenenti sezioni intestazione/scopo/cronologia coerenti con il dizionario dei dati
- Formattazione SQL che garantisce leggibilità e gestibilità
Ulteriori dettagli sulla mia implementazione dei file SOCS esulano dall'ambito di questo blog. Magari potrei dedicare un prossimo blog a questo argomento. Vi invito a mandarmi commenti e domande.
Che cos'è dunque un modello di dati?
Un breve riepilogo di questi livelli può aiutare a comprenderne lo scopo e come si supportano o si differenziano gli uni dagli altri nel processo di modellazione dei dati. Date uno sguardo a questa tabella:
| SPETTO DEL MODELLO DI DATI | OLISTICO | CONCETTUALE | LOGICO | FISICO |
|---|---|---|---|---|
| Silo di dati | √ | |||
| Relazioni tra silo di dati | √ | |||
| Nomi elementi | √ | |||
| Relazioni tra gli elementi | √ | |||
| Generalizzazioni degli elementi | √ | |||
| Voci degli elementi | √ | |||
| Nomi entità | √ | |||
| Relazioni tra entità | √ | |||
| Chiavi delle entità | √ | |||
| Attributi delle entità | √ | |||
| Vincoli delle entità | √ | |||
| Nomi tabelle/viste | √ | |||
| Nomi colonne | √ | |||
| Tipi di dati delle colonne | √ | |||
| Valori predefiniti delle colonne | √ | |||
| Chiavi primarie/esterne | √ | |||
| Nomi indici | √ | |||
| Proprietà indici | √ | |||
| Configurazioni dello spazio di archiviazione | √ |
Conclusione
Grazie per avermi seguito fin qui. La buona notizia è che abbiamo terminato! Finalmente. Mi auguro che abbiate trovato queste informazioni interessanti e che vi siano utili; se un buon sviluppatore Talend conosce i modelli di dati che utilizza, best practice e schemi di progettazione dei job emergono. Se non avete ancora letto i miei blog sull'argomento, ecco il collegamento alla Parte 4. Troverete i collegamenti alle Parti 1-2-3 all'interno. Potrebbe inoltre interessarvi il mio blog sulla realizzazione di un data lake gestito nel cloud, redatto in collaborazione con il vostro e mio caro amico Kent Graziano di Snowflake Computing, prezioso partner di Talend.
