Job Design Pattern e best practice Talend: parte 2
Il riscontro positivo con cui è stato accolto il mio ultimo blog dedicato ai Job Design Pattern e best practice Talend è motivo di grande soddisfazione per me. Un sentito grazie a tutti coloro che lo hanno letto! Vorrei invece invitare a leggerlo chi ancora non lo avesse fatto prima di procedere, in quanto questa Parte 2 è di fatto un approfondimento di quanto affrontato nel blog precedente. Mi sembra inoltre giunto il momento di addentrarci in argomenti più complessi, quindi preparatevi. La faccenda si farà interessante.
Introduzione ai Job Design Pattern
In qualità di sviluppatore Talend navigato, capire come gli altri progettano i loro job suscita sempre in me molto interesse. Usano le funzioni in modo corretto? Adottano uno stile riconoscibile oppure uno che non si è mai visto prima? Sono riusciti a trovare una soluzione perfetta? Oppure sono rimasti sopraffatti dalla natura astratta della "tela", dei dati dei componenti e/o del flusso di lavoro, addentrandosi in percorsi oscuri che non portano da nessuna parte? A prescindere dalle risposte a queste domande, credo che sia molto importante utilizzare lo strumento di cui disponiamo nel modo corretto e per lo scopo per cui è stato creato. Ecco perché mi sono imbarcato nell'impresa di illustrare i "Job Design Pattern" e le best practice di Talend. Mi sembra che anche una volta apprese tutte le caratteristiche e le funzionalità di Talend, persista l'esigenza di comprendere quale sia il modo migliore di sviluppare un job.
A rigor di logica, il "caso d'uso" è l'elemento trainante fondamentale di ogni job Talend. In realtà, ho visto molte variazioni differenti di uno stesso flusso di lavoro e tante diverse varietà di flussi di lavoro. La maggior parte di questi casi d'uso parte dalla premessa che un job di integrazione dati nella sua forma più semplice consiste nell'estrarre dati da una sorgente per poi elaborarli, magari trasformarli lungo il percorso, e infine caricarli in una destinazione posta altrove. Il codice ETL/ELT è, di conseguenza, la nostra linfa vitale. Si tratta del pane quotidiano per noi sviluppatori Talend, quindi non vi tedierò parlandovi di cose che già conoscete. Allarghiamo invece la nostra prospettiva...
Senza dubbio, l'ultima release di Talend (v6.1.1) è la migliore versione con cui io abbia mai lavorato. Grazie ai nuovi componenti per lavorare con i big data, Spark e l'apprendimento automatico, all'interfaccia utente rinnovata e agli strumenti di implementazione/integrazione continua (solo per citare alcune caratteristiche chiave), credo che si tratti della tecnologia per l'integrazione dei dati più affidabile e più ricca di funzioni attualmente disponibile sul mercato. D'accordo, sono un po' di parte, tuttavia, provo una certa empatia nei confronti di voi clienti, in quanto mi sono trovato nei vostri panni, quindi mi auguro che possiate giudicare da soli il valore reale di questa soluzione.
I tre elementi fondamentali di un progetto di integrazione dati di successo
Sarete tutti d'accordo che uno sgabello non può reggersi in piedi senza almeno tre gambe, giusto? Lo stesso vale per lo sviluppo software. Sono tre gli elementi fondamentali necessari per creare e distribuire un progetto di integrazione dati valido:
- Caso d'uso – ovvero un requisito ben definito per i dati di business/flusso di lavoro
- Tecnologia – strumenti con cui la soluzione viene creata, implementata ed eseguita
- Metodologia – un modo di procedere su cui tutti concordano
Tenendo presente queste premesse e avendo già definito delle "Linee guida di sviluppo" (se avete letto il mio precedente blog saprete di cosa parlo), partiamo da questi requisiti.
Ampliamento delle basi
Se i job Talend includono la tecnologia in un flusso di lavoro per un caso d'uso, i Job Design Pattern rappresentano la metodologia migliore per svilupparli. Se nulla di ciò che condivido in questi blog vi può essere utile, almeno cercate di creare i vostri job in modo coerente. Se avete sviluppato un modello migliore che per voi è efficace, ottimo! Continuate così senza modificare nulla. Ma se invece continuate ad avere problemi a livello di prestazioni, riutilizzabilità e sostenibilità o se dovete continuamente rielaborare il codice per adattarlo a requisiti in evoluzione, allora queste best practice vi possono essere d'aiuto.
9 ulteriori best practice da prendere in considerazione:
Ciclo vitale di sviluppo del software (SDLC)
"Persone, prodotto e processo", secondo quanto afferma il miliardario Marcus Leminos in "The Profit" (CNBC), sono i tre elementi chiave per determinare il successo o il fallimento di un progetto di business. E io sono d'accordo! Il processo SDLC è la fase in cui il gioco si fa serio per un qualsiasi team di sviluppo software. Affrontarlo nel modo corretto è fondamentale, mentre ignorandolo si rischia di compromettere il progetto o addirittura di determinarne il fallimento. La Guida alle best practice SDLC di Talend offre un approfondimento su concetti, principi, specifiche e dettagli relativi alle funzioni di integrazione e implementazione continue disponibili per gli sviluppatori Talend. Consiglio caldamente a tutti i team di sviluppo software di incorporare le best practice SDLC nelle "Linee guida di sviluppo" che ho illustrato nel mio precedente blog di questa serie. E di metterle in pratica!
Gestione degli spazi di lavoro
Una volta installato Talend Studio sul laptop o sulla workstation (ipotizzando che abbiate diritti di amministratore), viene generalmente creata una directory Workspace predefinita all'interno del disco rigido locale e, come accade in molte installazioni software, questa directory predefinita si trova all'interno della directory dove vengono collocati i file eseguibili. Onestamente, non credo che si tratti di una prassi efficace. Vi spiego perché.
Le copie locali dei file di progetto (metadati dei job e dei repository) vengono memorizzate in questa directory Workspace e quando vengono associate a un sistema di controllo del codice sorgente (come SVN o GIT) tramite il Talend Administration Center (TAC), esse vengono sincronizzate ogni volta che si apre un progetto e si salvano degli oggetti. Credo che questi file debbano risiedere in un luogo facilmente identificabile e gestibile. Preferibilmente in un'altra directory del disco (o addirittura su un altro disco locale).
Per essere più chiaro, ogni volta che si crea una qualsiasi connessione in Talend Studio, viene utilizzato uno spazio di lavoro (workspace). Può trattarsi di una connessione "locale" o "remota", con la differenza che la prima non viene gestita dal TAC mentre la seconda sì. I nostri clienti in abbonamento normalmente utilizzano la connessione "remota".
La modalità di organizzazione della struttura di directory dovrebbe essere chiaramente descritta nelle "Linee guida di sviluppo" e adottata dal team, per una cooperazione e collaborazione ottimali. È fondamentale concordare su una strategia che risulti efficace per l'intero team, ispiri disciplina e sia coerente.
Progetti di riferimento
Utilizzate dei progetti di riferimento? Sapete di cosa si tratta? Mi sono reso conto che molti nostri clienti non conoscono questa semplice, ma estremamente produttiva funzionalità. Tutti desideriamo creare un codice comune o generico, riutilizzabile e condivisibile tra più progetti. Spesso vedo sviluppatori aprire un progetto, copiare un frammento di codice e incollarlo in un progetto o job separato (talvolta uguale). O ancora esportare oggetti da un progetto per importarli in un altro. Io stesso mi dichiaro colpevole! Ho adottato entrambe queste pratiche in passato. Nonostante si tratti di un sistema che fondamentalmente funziona, non è corretto; crea infatti enormi problemi a livello di manutenzione, come forse molti di voi che si sono lasciati intrappolare da questa procedura avranno scoperto. Quindi aspettate! Esiste un sistema migliore: i progetti di riferimento! Scoprirli mi ha dato molta soddisfazione.
Se avete usato il TAC per creare dei progetti, forse avrete notato una casella di controllo denominata "Reference". Vi siete mai chiesti a cosa serve? Se create un progetto e selezionate quella casella di controllo per renderlo un progetto di riferimento, esso risulterà disponibile per essere incluso o collegato a un qualsiasi altro progetto. Il codice creato nel progetto di riferimento risulterà disponibile (per la sola lettura) nei progetti a esso collegati, diventando altamente riutilizzabile. Questo è il modo corretto di creare oggetti comuni e codice condiviso.

Questi progetti di riferimento devono tuttaviarestare limitati; consiglio di conservarne uno solo come best practice, tuttavia, in alcuni casi, è possibile averne di più (2 o 3). Avvertenza: creare troppi progetti di riferimento può vanificarne lo scopo, quindi non esagerate. Gestirli in modo corretto è molto importante; le regole per il loro uso dovrebbero essere chiaramente descritte nelle "Linee guida di sviluppo" e adottate dall'intero team, per una cooperazione e collaborazione ottimali.
Convenzioni di denominazione degli oggetti
"Che cosa c'è in un nome? Ciò che chiamiamo rosa anche con un altro nome conserva sempre il suo profumo." Chi lo diceva?
Lasciate stare, non importa. Le convenzioni di denominazione invece sì, sono importanti! Ogni team di sviluppo che si rispetti lo sa e ne fa pratica. A prescindere da quando, con cosa e come vengono applicati i nomi degli oggetti Talend, la coerenza è ancora una volta alla base della buona riuscita di un progetto. Le convenzioni di denominazione degli oggetti in Talend dovrebbero essere chiaramente descritte nelle "Linee guida di sviluppo" e adottate dall'intero team, per una cooperazione e collaborazione ottimali (sembra che questa frase si ripeta di frequente...).
Repository dei progetti
Quando un progetto viene aperto in Talend Studio, ovvero nell'IDE (Integrated Development Environment) di Eclipse o semplicemente nell'editor dei job, il riquadro di sinistra rappresenta il "Project Repository" o repository dei progetti. È qui che risiedono tutti gli oggetti dei progetti. Il repository è costituito da una serie di sezioni molto importanti. Sicuramente conoscerete le sezioni "Job Designs", ottimizzate nella versione 6.1.1 per includere i tre diversi tipi di job che create (integrazione dati, batch e streaming), ma vi sono anche altre sezioni che è importante conoscere e utilizzare.
- Context Groups (Gruppi di contesto) – Anziché creare variabili di contesto integrate nel job, createle in un gruppo di contesto inserito nel repository, quindi riutilizzatele in tutti i job (e nei progetti, se incluse in un progetto di riferimento). I gruppi devono essere allineati in modo efficace; è buona prassi creare dei gruppi per i vari ambienti utilizzati: SBX/DEV/TEST/UAT/PROD, dove DEV è l'impostazione predefinita; rimuovete le impostazioni di contesto predefinite esistenti.

Come avrete notato, ho aggiunto una variabile di contesto "SysENVTYPE" contenente il valore per la programmabilità dinamica all'interno di un ambiente selezionato. In altre parole, uso questa variabile all'interno di un job per determinare, in fase di runtime, quale ambiente è attualmente in esecuzione, in modo da poter alterare in maniera programmatica il flusso, utilizzando una logica condizionale.
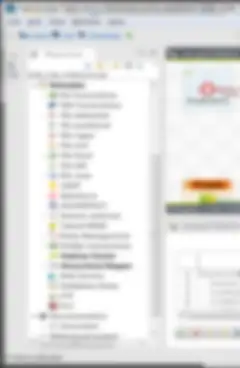
- Metadata (Metadati) – Sono disponibili varie forme di metadati; potete utilizzarli tutti! Connessioni DB e relativi schemi di tabelle, layout di file flat di ogni tipo (.csv, .xml, .json e altri), oltre al sempre utile "schema generico", utilizzabile in così tanti modi che non sto neanche ad elencarli in questo blog, perché non finirei mai.
- Documentation (Documentazione) – Generate un vostro progetto Wiki e pubblicatelo a uso del team; questa funzione consentirà di produrre un set completo di file html sul progetto da consultare con la massima praticità. Una cosa estremamente semplice che richiede solo pochi minuti.
Ovviamente, includete alcune best practice per il team nelle "Linee guida di sviluppo" e adottatele. Potete modificarle ogni volta che è necessario, ma fate in modo che tutto il team sia coinvolto.
Controllo versioni (branching e tagging)
Come avrete notato, in ogni scheda delle proprietà job è possibile impostare schemi di numerazione delle versioni, indicando con una 'M' (Major) la principale e con una 'm' (minor) le secondarie. Inoltre, è possibile impostare uno stato di vostra definizione le cui possibilità predefinite sono "development" (sviluppo), "test" e "production" (produzione). AVVERTENZA: questi stati predefiniti sono pensati per il singolo sviluppatore (TOS: Talend Open Studio) che non può sfruttare le funzionalità di sviluppo collaborativo e di controllo del codice sorgente (SCC) dei repository SVN/GIT. È importante tenere presente che ogni volta che si modificano queste proprietà interne del job, una copia completa del job viene creata nello spazio di lavoro locale e sincronizzata con il sistema di controllo del codice sorgente. Ho visto progetti in cui venivano effettuate copie dei job dopo più di una decina di aggiornamenti interni della versione. TUTTE le copie del job vengono copiate, andando a creare un proliferare di file subordinati da sincronizzare nel sistema SCC. Tutto ciò può andare ad appesantire il progetto e causare seri problemi a livello di prestazioni all'apertura e chiusura del progetto. Se riscontrate questo genere di problematiche, significa che è necessario ripulire lo spazio di lavoro esportando le vecchie versioni e importando solo la versione principale del job. Si tratta di una procedura lunga e complessa, ma ne vale sicuramente la pena.
Quindi la best practice per il controllo delle versioni negli ambienti in abbonamento consiste nell'utilizzare il meccanismo nativo di branching e tagging del sistema SCC. Si tratta del modo migliore di gestire le varie release di una versione di un progetto, in quanto il sistema di controllo del codice sorgente, a ogni salvataggio del job, mantiene solo le informazioni delta. In questo modo lo spazio necessario per il salvataggio della cronologia di un particolare job si riduce drasticamente. Ideate uno schema di controllo delle versioni che utilizzi numeri, date o qualche altro particolare utile, illustratelo dettagliatamente nelle "Linee guida di sviluppo" e fate in modo che l'intero team adotti la procedura (ormai avrete capito).
Gestione della memoria
Pronti a eseguire il vostro job? Avete considerato di quanta memoria ha bisogno? Il flusso di dati dovrà elaborare milioni di righe e/o molte colonne e/o numerosi riferimenti in tMap? Avete calcolato che quando il job viene eseguito nel "Job Server" altri job potrebbero essere eseguiti in simultanea? Il "Job Server" su cui verrà eseguito il job presenta un numero di core e/o una quantità di RAM sufficienti? Come avete configurato le unioni tMap? Avete utilizzato "Load Once" (Carica una sola volta) oppure "Row by row" (Riga per riga)? Il job da eseguire richiama job figlio oppure viene a sua volta chiamato da un job padre? E quanti livelli di job nidificati sono previsti? I job figlio vengono eseguiti su una JVM separata? Se state sviluppando job ESB, sapete quanti percorsi vengono creati? State utilizzando tecniche di parallelizzazione (illustrate di seguito)? Beh? Avete preso in considerazione tutti questi fattori? Eh? Scommetto di no…
Le impostazioni predefinite hanno lo scopo di fornire valori di base per configurazioni più dettagliate. I job presentano diverse impostazioni predefinite, incluse quelle per l'allocazione della memoria. Tuttavia i valori predefiniti non sono sempre corretti, anzi il più delle volte sono sbagliati. I valori in corrispondenza di Use Case Job Design (Progettazione job per caso d'uso), Operational Ecosystem (Ecosistema operativo) e Real Time JVM Thread Count (Conteggio thread JVM in tempo reale) determinano la quantità di memoria utilizzata. Tutti questi valori devono essere gestiti.

È possibile specificare le impostazioni di memoria della JVM a livello di progetto per job specifici (come sopra):
Preferences (Preferenze) > Talend > Run (Esegui)
Vi consiglio di farlo o ne pagherete le conseguenze! La gestione della memoria viene spesso trascurata e, nell'ambito di un team, è necessario definire delle linee guida da seguire sia in fase di sviluppo che in fase operativa. Vi ho finalmente convinto a leggere il mio primo blog?
Sintassi SQL dinamica
Molti dei componenti di database input richiedono una sintassi SQL corretta per essere inclusi nella scheda Basic Settings (Impostazioni di base). Ovviamente, è possibile inserire la sintassi direttamente nel componente tMyDBInput, non vi è nulla di sbagliato. Tuttavia, considerando la necessità di dover creare in modo dinamico una query SQL complessa al runtime, sulla base di una logica di attenuazione controllata dal job, o dal relativo job padre, un approccio di questo tipo potrebbe apparire piuttosto semplicistico. Create piuttosto delle variabili di contesto per i costrutti di base della query SQL, impostatele nel flusso del job prima di arrivare al componente tMyDBInput, quindi usate la variabile di contesto al posto di una query codificata.
Ad esempio, io ho sviluppato un gruppo di contesto all'interno di un repository di progetti di riferimento che ho chiamato "SystemVARS" e che include diverse variabili utili e riutilizzabili. Per il paradigma SQL dinamico, ho definito le seguenti variabili "String", inizializzate su "null":

Ho configurato queste variabili all'interno di un componente tJava in base alle mie esigenze, quindi le ho riunite nel campo della query tMyDBInput, in questo modo:
"SELECT " + Context.sqlCOLUMNS + Context.sqlFROM + Context.sqlWHERE
Come si può notare, includo sempre uno spazio al termine del valore della variabile, in modo che la concatenazione risulti "pulita". Se è necessario ulteriore controllo, utilizzo anche una variabile "sqlSYNTAX" e controllo in modo condizionale come vengono concatenate le clausole della sintassi SQL, quindi posiziono semplicemente Context.sqlSYNTAX nel campo della query tMyDBInput. Ecco fatto! È vero, non si tratta di sintassi SQL dinamica dalla prospettiva dell'host del database, ma è comunque una sintassi SQL generata dinamicamente per il job.
Tutti in coro adesso: "definite una linea guida e fate in modo che tutti la applichino di comune accordo!"
Opzioni di parallelizzazione
Talend offre diversi meccanismi che consentono la parallelizzazione del codice. Se utilizzate correttamente, in modo efficiente e tenendo in seria considerazione il potenziale impatto sul core della CPU e sull'utilizzo della RAM, queste opzioni consentono di creare Job Design Pattern dalle elevate prestazioni. Diamo un'occhiata alle opzioni disponibili:
- Piano di esecuzione – È possibile configurare più job/attività da eseguire in parallelo dal TAC.
- Flussi di lavoro multipli – È possibile fare partire, all'interno di un unico job, più flussi di dati che condividono lo stesso thread; se non sussistono dipendenze tra i flussi di dati, questa tecnica può essere utilizzata in rari casi d'uso; generalmente io la evito, preferisco creare job separati.
- Job padre/figlio – Quando un job figlio viene chiamato con il componente tRunJob, è possibile selezionare la casella "Use an independent process to run subjob" (Usa un processo indipendente per eseguire il sotto-job) e stabilire un heap/thread JVM separato in cui eseguire il job figlio; anche se questa non è una vera e propria parallelizzazione, si tratta di una tecnica molto simile.
- Componenti – Il componente tParallelize collega più flussi di dati per l'esecuzione; i componenti tPartitioner, tDepartitioner, tCollector e tRecollector offrono il controllo diretto sul numero di thread paralleli di un flusso di dati.
- Componenti DB – La maggior parte dei componenti DB Input/Output offre un'impostazione avanzata che permette di abilitare la parallelizzazione del numero di thread su specifiche istruzioni SQL; questa tecnica può risultare estremamente efficace, tuttavia se si imposta un numero di thread troppo elevato si può ottenere l'effetto opposto; il numero ideale è tra 2 e 5.
È possibile utilizzare tutti questi metodi di parallelizzazione in combinazione tra loro, nidificati in base alle necessità, tuttavia è bene tenere sempre presente la quantità di memoria disponibile. È importante non perdere mai di vista il flussi di esecuzione dei Job Design Pattern. Le opzioni di parallelizzazione sono disponibili unicamente nella piattaforma Talend come funzionalità avanzata. Non includete opzioni di parallelizzazione nelle Linee guida di sviluppo.
Il segreto per realizzare job Talend di successo
Mi auguro che queste best practice per la definizione di Job Design Pattern influenzeranno la vostra opinione su quale sia il modo migliore di creare job Talend. Sostanzialmente, per una buona riuscita di un job è necessario rispettare linee guida, disciplina e coerenza. Basta decidere di farlo e applicarsi. Mentre tracciate il vostro codice sulla "tela" dei dati/flussi di lavoro, ricordate:
"La vera chiave del successo è l'azione!" – Pablo Picasso
Per finire, eccovi un elenco di cose da fare e da evitare che, credo, racchiudano la ricetta segreta per la realizzazione di job Talend di successo:
- - Usare sia il componente tPreJob che tPostJob
- - Non imbrattare la "tela" con componenti raggruppati in modo troppo serrato, ma distribuirli uniformemente
- - Impaginare il codice in modo ordinato, dall'alto verso il basso e da sinistra a destra
- - Non aspettarsi di riuscire al primo tentativo
- - Identificare il loop principale del job e controllare l'uscita
- - Non ignorare le tecniche di gestione degli errori
- - Usare i gruppi di contesto in modo diffuso (DEV/QA/UAT/PROD) e ponderato
- - Non creare layout enormi di singoli job
- - Creare moduli job di piccole dimensioni
- - Non forzare la complessità, ma prediligere la semplicità
- - Usare schemi generici ovunque (l'unica eccezione è lo schema a colonna singola)
- - Non dimenticare di assegnare un nome agli oggetti
- - Usare joblet ove appropriato (potrebbe essere possibile solo in pochi casi)
- - Non utilizzare in modo eccessivo il componente tJavaFlex; tJava o tJavaRow sono più che sufficienti
- - Generare/pubblicare la documentazione del progetto una volta approntata
- - Non dimenticare di configurare l'allocazione di memoria al runtime
Conclusione
Eccoci. Siamo giunti alla fine. Siete soddisfatti? Mi auguro di no, perché sto pensando di continuare con altri blog di questa serie: "Casi d'uso di esempio"! Nel blog di oggi
abbiamo approfondito i concetti fondamentali e introdotto alcuni elementi avanzati che ritenevo opportuno portare alla vostra attenzione. Spero che vi sia stato utile. Se vi sentite, lasciate un vostro commento sulle best practice da voi utilizzate, se possibile, intavolando proficue conversazioni piuttosto che diatribe. Alla prossima!
Risorse correlate
Introduzione a Talend Open Studio for Data Integration
Prodotti menzionati

Altri articoli correlati
- "Job Design Pattern e best practice Talend": Parte 4
- "Job Design Pattern e best practice Talend": Parte 3
- Che cos'è la migrazione dei dati?
- Che cos'è la mappatura dei dati?
- Che cos'è la Data Integration?
- Migrazione dei dati: strategia e best practice
- Job Design Pattern e best practice Talend: parte 1
- Change Data Capture (CDC)
- Guida per sviluppatori alla migrazione da Informatica PowerCenter a Talend: Parte 1