Talendのジョブ設計パターンとベストプラクティス(第3部)
このトピックに関する前回のブログ記事は大変好評だったようです。熱心な読者の皆様、ありがとうございます。
過去のブログ記事をまだ読んでいない方は、まずはこちら(Talendのジョブ設計パターンとベストプラクティス第1部と第2部)をお読みください。それぞれ異なるテーマを取り上げています。
ジョブ設計パターンとベストプラクティスの解説を始める前に、お知らせがあります。これまでのコンテンツを90分のテクニカルプレゼンテーションにまとめました。このプレゼンテーションは、「Talend Technical Boot Camps」にて、世界中で視聴いただけます。地域のイベントスケジュールは、TalendのWebサイトでご確認ください。プレゼンテーションでお会いできることを楽しみにしています。
このシリーズの内容について、コメント、質問、論点をお寄せください。ディスカッションを膨らませ、Talendコミュニティで展開できれば、と思います。「標準」ではなく「ガイドライン」であることを思い出してください。どうか、ご意見をお寄せいただき、ご協力をお願いいたします。
テーマを深める
Talendプロジェクトをはじめとするソフトウェアライフサイクルを成功へと導くには、「開発者のガイドライン」の確立が不可欠であることを理解いただけたと思います。では、次に進みましょう。開発者のガイドラインの確立、チームによる採用、規律の段階的な浸透は、Talendで極めて大きな成功を収めるための鍵である、という点を解説します。これに、異論を唱える人はいないでしょう。Talendジョブの作成には、複雑な手順が必要です(ここでは詳しい説明はしません)。したがって、「ビジネスユースケース」、「テクノロジー」、「手法」を理解することによって、成功の確率が高くなります。時間をかけて、チームのガイドラインを作成することには十分な価値がありますし、成果があるはずです。
Talendユーザーが取り組んでいるユースケースの多くは、何らかの形でデータ統合プロセスに関連しています。データ統合はTalendのコアコンピテンシーであり、データの移動を意味します。データフローはさまざまな形態で発生するため、処理や操作の方法が重要になります。その重要性は非常に大きく、作成するあらゆるジョブの本質であるとも言えます。ビジネスデータの移動というユースケースにおいてTalendをテクノロジースタックの不可欠な要素として使用する場合、どのような手法を使用すればよいでしょうか。それはもちろん、これまでに解説したSDLCベストプラクティスなのですが、それだけではありません。データに関連する手法ですから、データモデリングも含まれます。これは、私の専門分野でもあります。私は、25年以上にわたるデータベースアーキテクトという経験の中で、数え切れないほどのデータベースソリューションの設計と構築に携わってきました。ですから、データベースシステムにもライフサイクルがあることを実感しています。フラットファイル、EDI、OLTP、OLAP、STAR、Snowflake、データボルトといったスキーマを問わず、データとそのスキーマが生成され、廃棄に至るまでのプロセスを無視することは、チームにとって弱点になり、最悪の場合は大惨事につながるのです。
このブログではデータモデリング手法は扱いませんが、適切なデータ構造設計を採用し、それに沿って使用することが非常に重要です。ぜひデータボルトのシリーズの記事をお読みいただき、今後掲載予定のデータモデリングの記事もご覧ください。現時点では、DDLC(Data Development Life Cycle)はベストプラクティスです。このことについて考えていただければ、私の意図を後で理解できるでしょう。
さらなるジョブ設計のベストプラクティス
では、Talendのジョブ設計について、「ベストプラクティス」をさらにいくつかご紹介します。ここまでで、16のベストプラクティスを解説しました。あと8つあるのでお楽しみに(このシリーズには第4部があります。すべてを盛り込むことはできないので、記事を読みやすく分割しています)。
さらに検討すべき8つのベストプラクティス
コードルーチン
状況によって、Talendコンポーネントではプログラミングのニーズを満たせない場合があります。それでも問題はありません。TalendはJavaコードジェネレーターです。キャンバスに配置し、プロセスやデータフローで使用できるPure Javaコンポーネントもあります。それでもニーズに対応できない場合があるはずです。そのようなときには、コードルーチンが役立ちます。これは、プロジェクトリポジトリに追加可能なJavaメソッドです。基本的に、ユーザー定義のJava関数であり、ジョブ内のさまざまな場所で使用できます。
Talendは数多くのJava関数を備えています。すでに使用されていると思います。
getCurrentDate
- sequence(String seqName, int startValue, int step)
- ISNULL(object variable)
ジョブ、プロジェクト、ユースケースの全体像を考えた場合、コードルーチンにはさまざまな用途があります。ここで基本となるのは、再利用可能なコードです。それには、汎用な方法でジョブを合理化できるコードルーチンを作成することを、常に念頭に置く必要があります。適切なコメントを指定すれば、関数を選択する際に役立つテキストとして表示されます。

リポジトリスキーマ
プロジェクトリポジトリのMetadataセクションでは、再利用可能なオブジェクトを作成することが可能です。これは、重要な開発ガイドラインですね。リポジトリスキーマは、ジョブで再利用可能なオブジェクトを作成する強力な手法です。以下が含まれます。

- Delimited
- Positional
- RegEx
- XML
- Excel
- JSON
- 汎用スキーマ - さまざまなレコード構造のマッピングに使用します。
- WDSLスキーマ - Webサービスメソッド構造のマッピングに使用します。
- LDAPスキーマ - LDAP構造(LDIFも使用可能)のマッピングに使用します。
- UN/EDIFACT - 幅広いEDIトランザクション構造のマッピングに使用します。
スキーマの作成では、オブジェクト名、目的、説明、ジョブコードで参照するメタデータオブジェクト名を指定します。デフォルトでは「metadata」となりますので、命名規則を定義してください。命名規則を適用しないと、すべて同じ名前が割り当てられてしまいます。「md_{オブジェクト名}」などがわかりやすい例ですが、右図を参考にしてください。
汎用スキーマは、特定のニーズを満たすデータ構造の作成に使用するという点で、特に重要です。同じ図の「Db Connection」では、物理データ接続からリバースエンジニアリングで作成したテーブルスキーマが表示されています。「accounts」テーブルには12のカラムがあります。ところが、下に表示されている汎用スキーマのカラム数は16です。追加されたカラムは、「accounts」テーブルに追加された値の要素であり、ジョブデータフロープロセスで追加データの取得に使用されます。元のデータベーステーブルには恐らく100を超えるカラムがあり、このジョブデータフローに必要なカラムは10個のみであるため、必要な10カラムを持つテーブルへのクエリー用に、汎用スキーマを定義します。これは、非常に便利な機能です。この作業でのアドバイスは、汎用スキーマを大いに活用することです。ただし、カラムが1つのみの構造は例外であり、単にそのまま組み込むことをお勧めします。
SAP、Salesforce、NoSQL、Hadoopクラスターなどの接続タイプには、スキーマ定義を行う機能が含まれています。
Log4J
Apache Log4Jは、Talend v6.0.1から使用可能であり、堅牢性に優れたJavaログ管理フレームワークを提供します。現在、すべてのTalendコンポーネントがLog4Jサービスをサポートしており、前のブログ記事で説明したエラー処理手法が拡張されています。皆さんは、すでにこのベストプラクティスをプロジェクトに適用していると思います。Log4Jによる機能拡張をご活用ください。
Log4Jを使用するには、有効化が必要です。この操作は、プロジェクトプロパティのセクションで実行できます。このセクションでは、Console(stderr/stdout)とLogStashアペンダーで一貫したメッセージングパラダイムを提供するためのログ管理ガイドラインを指定できます。このセクションで、アペンダーを一括定義することにより、TalendジョブでLog4J機能を使用する方法がシンプルになります。Log4J構文のレベル値は、お馴染みのINFO/WARN/ERROR/FATALに相当します。
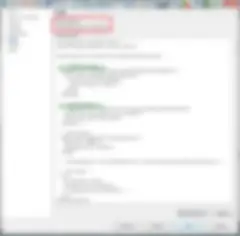
Talend Administrator Center(TAC)でジョブを実行するタスクを作成するとき、ログに記録するLog4Jレベルを設定できます。DEV/TESTおよびPRODの各環境に適切な設定を行ってください。ベストプラクティスとしては、DEV/TESTをINFOレベル、UATをWARNレベル、PRODをERRORレベルに設定します。これ以上のレベルを設定することも可能です。

tWarnコンポーネントおよびtDieコンポーネントと新しいログサーバーの連携については、Log4Jでは実行の監視と追跡機能が大幅に拡張されています。この機能を使用して、チームの開発ガイドラインを確立してください。
Activity Monitor Console(AMC)
Talendは、統合型のアドオンツールを提供しています。このツールは、収集したアクティビティの詳細な処理情報をデータベースに統合することで、ジョブ実行の監視を拡張します。グラフィカルインターフェイスを備え、StudioとTACからのアクセスが可能です。開発者と管理者に、コンポーネントとジョブのインタラクションの把握、想定外のエラーの回避、システム管理に関する重要な意思決定のサポートを提供します。この機能はオプションなので、AMCデータベースとWebアプリのインストールが必要です。AMCコンポーネントのインストールについては、Talend Activity Monitoring Console User Guideで詳しく解説されているので参照してください。では、使用に関するベストプラクティスをご紹介します。

AMCデータベースには、次の3つのテーブルが含まれます。
- tLogCatcher - Java例外やtWarn/tDieコンポーネントから送信されたデータを格納
- tStatCatcher - 個々のコンポーネントにある[tStatCatcher Statistics]チェックボックスから送信されたデータを格納
- tFlowMeterCatcher - tFlowMeterコンポーネントから送信されたデータを格納
これらのテーブルにはAMC UIのデータが格納されます。AMC UIは、このデータに基づいてジョブのアクティビティを可視化する、堅牢性に優れた機能を備えています。プロジェクトの設定タブで適切なログの優先度を選択し、DEV/TEST/PRODの各環境で実行するジョブに適用するデータ制限を慎重に検討してください。[Main chart]ビューでは、PROD環境へのリリース前に、ジョブ設計のボトルネックを特定および分析できます。また、エラーレポートでは、特定の時間範囲内で発生したエラー率の分析も可能です。

テーブルには、これ以外にも有効な用途があります。テーブルはデータベース内に存在するため、SQLクエリーを記述することによって貴重な情報を抽出できます。スクリプティングツールを使って設定することで、自動クエリーを生成し、特定の条件でAMCデータベースにログを記録する通知を行うことが可能です。リターンコードの手法(ジョブ設計パターンに関するシリーズの第1部で説明)を確立することで、クエリーを使って、オペレーションをプログラム的に自動実行できます。これは、非常に効果的な方法です。
リカバリチェックポイント
実行時間の長いジョブはありませんか。長いジョブは、重要なステップの1つでエラーが発生すると最初から実行しなおさなければならないため、非常に煩雑です。ジョブフロー内で、エラー発生直前のポイントでジョブを再開できれば、時間と手間を最小限に抑えることが可能になります。TACは、ジョブでエラーが発生した場合の実行復旧機能を備えています。ジョブ設計でこの「リカバリポイント」を戦略的に配置しておけば、エラーが発生してもジョブを続行でき、最初からやり直す必要はなくなります。

エラーが発生した場合は、TACの[Error Recovery Management]タブでエラーを確認し、ジョブ処理を続行できます。これは、非常に優れた機能です。

ジョブレット
ジョブレットとは、「1つまたは複数のジョブに必要に応じて追加できる、再利用可能なジョブコード」と説明しましたが、実際にジョブレットが有効なユースケースはあまり多くありません。つまり、有効なユースケースは宝石のように貴重ですから、見つけた場合はぜひ使用してください。ジョブレットは、次に示すように、さまざまな方法で作成および使用できます。
ジョブレットの新規作成では、入出力コンポーネントが自動的にキャンバスに追加されます。ここから、ジョブレットを使用するジョブワークフローへと、入出力となるスキーマを割り当てることができます。ジョブレットは一般的に、値の受け渡しに使用されますが、その処理内容はニーズによってさまざまです。次の例では、行を受け取った後、データベーステーブルの更新と、標準出力へのログ記録を行い、同じ行を(この例では)そのまま渡しています。

これよりも一般的ではありませんが、入力と出力のいずれかまたは両方のコンポーネントを削除することで、特殊なデータ/プロセスフローを処理するユースケースがあります。次の例では、ジョブレットとの受け渡しは発生しませんが、tLogCatcherコンポーネントは、以降の処理で選択されるさまざまな例外を監視します(これについては、エラー処理のベストプラクティスで説明しました)。
このように、ジョブレットによってコードの再利用性が格段に高まることは明らかです。ジョブレットを参照オブジェクトで使用することにより、複数のプロジェクトでの活用が可能になります。
コンポーネントのテストケース
Talend v6.0.1以前を使用している方は、ここの内容を無視してください。ただし、簡単なアップグレードなので、ぜひアップグレードしてください。ジョブ内でテストケースを作成する新機能は、私のお気に入りです。これは、厳密には「ユニットテスト」ではなく、コンポーネントテストです。実際には親ジョブに関連付けられたジョブであり、具体的には特定のコンポーネントをテストしています。すべてのコンポーネントがテストケースをサポートしているわけではありませんが、データフロー入力を取得して出力するコンポーネントであれば、テストケースを作成できます。
コンポーネントテストケースを作成するには、コンポーネントを選択して右クリックし、メニューの一番下にある[Create Test Case]を選択します。このオプションを選択すると、ジョブが新規作成され、テストケースの機能テンプレートが開きます。ここには、テスト対象のコンポーネントと、組み込みの入出力コンポーネントがデータフロー内で[Input File]と表示されます。ここからデータを処理し、テスト対象コンポーネントにレコードを渡して処理を実行した後、結果を[Result File]に書き出します。処理が完了すると、想定される結果である[Reference File]と結果ファイルが比較され一致するかどうかに基づいて成否が判定されます。非常にシンプルなので、例を挙げて説明しましょう。
これは、すでに例に登場したジョブです。tJavaFlexコンポーネントでデータフローを操作し、その下のダウンストリームへと渡しています。

このようなテストケースジョブが作成されます。変更は必要ありません(ただし、キャンバスを少しクリーンナップしました)。
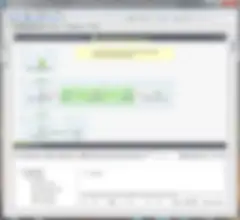
テストケースジョブのコードを変更することは可能ですが、テスト対象コンポーネントの変更は、親ジョブのみで行うべきです。たとえば、スキーマの変更が必要な場合は、親ジョブ(またはリポジトリ)を変更します。これにより、テストケースに変更内容が継承されます。緊密に接続されているため、スキーマによって結合されます。
ケースとケースの「インスタンス」が作成されると、同じテストケースジョブで実行する「入力」ファイルと「参照」ファイルを複数作成できます。これにより、良好/不良なテストデータ、小規模/大規模なテストデータ、特殊なテストデータのテストが可能になります。テストの対象だけでなく、テストに使用するデータも慎重に検討してください。
Nexusアーティファクトリポジトリを使用し、テストケースジョブと親ジョブを一緒に保存する場合、Jenkinsのようなツールを使用してテスト実行を自動化し、次の環境にジョブを移行できるかどうかを判定できます。
データフローの「反復」
皆さんは、Talendコード開発で、「トリガー」プロセスや「行」データフローコネクターを使ってコンポーネントをリンクしたことがあるはずです。開始コンポーネントを右クリックし、次のコンポーネントにリンクする「ライン」をつなぐことで、リンクが確立されます。プロセスフローリンクは、「OnSubJobOk/ERROR」、「OnComponentOK/ERROR」、「RunIF」のいずれかであり、これについては前のブログ記事で説明しました。データフローリンクは、動的に接続されると「row{x}」という名前が割り当てられます。この「x」は、一意のオブジェクト名/行名を示す数字であり、自動的に割り当てられます。データフローリンクの名前はカスタマイズが可能ですが(命名規則のベストプラクティス)、このリンクを確立することで、コンポーネント間のデータスキーマがマッピングされ、データの受け渡しを行う「パイプライン」となります。実行時にこのリンクで渡されるデータは、データセットとして参照されます。ダウンストリームコンポーネントに応じて、カプセル化されたサブジョブ内でデータセット全体が処理されます。
このように一括処理ができないデータセット処理も存在し、データフローの直接制御が必要な場合もあります。このような処理では、「行ごと」の処理または「反復」処理で制御します。次のコードを見てください(意味のある処理は行っていません)。

tIterateToFlowコンポーネントとtFlowToIterateコンポーネントに注目してください。この特殊なコンポーネントでは、データフロー処理にコントロールを配置することで、データベースの反復を行単位で実行できます。この「リストベース」の処理は、必要に応じて使用すると非常に便利です。ただし、データフローを行単位の反復に分割する場合、すべてをデータセットに統合しないと処理を実行できない場合が多いので、注意が必要です(例で示すtMapなど)。これは、一部のコンポーネントは「行」データセットフローを強制し、「反復的」データセットフローを処理できないことが原因です。また、t{DB}Inputコンポーネントは、行メニューで「メイン」と「反復」両方のデータフローオプションを提供する点にも注意してください。
Talendヘルプセンターと「Component Reference Guide」に掲載されているデータフローをリストに変換するシナリオとファイルのリストをデータフローとして変換するシナリオをサンプルとして参照してください。この機能の使用方法がわかりやすく説明されています。この機能を活用する際には、用途を説明したラベルを付けてください。
まとめ
第3部は以上です。いかがだったでしょうか。次回の第4部は、Talendコードの作成に役立つジョブ設計パターンとベストプラクティスの最終回になります。「サンプルユースケース」についてもご紹介する予定ですので、お楽しみに。以上のベストプラクティスを理解することにより、抽象的なアプリケーションを理解できるようになります。皆さんからのコメント、質問、論点などをお待ちしております。
