What is Apache Spark?
Today some of the world’s biggest companies are leveraging the power of Apache Spark to speed big data operations. Organizations of all sizes rely on big data, but processing terabytes of data for real-time application can become cumbersome. Can Spark’s blazing fast performance benefit your organization?
What is Apache Spark?
Apache Spark is an ultra-fast, distributed framework for large-scale processing and machine learning. Spark is infinitely scalable, making it the trusted platform for top Fortune 500 companies and even tech giants like Microsoft, Apple, and Facebook.
Spark’s advanced acyclic processing engine can operate as a stand-alone install, a cloud service, or anywhere popular distributed computing systems like Kubernetes or Spark’s predecessor, Apache Hadoop, already run.
Apache Spark generally requires only a short learning curve for coders used to Java, Python, Scala, or R backgrounds. As with all Apache applications, Spark is supported by a global, open-source community and integrates easily with most environments.
Below is a brief look at the evolution of Apache Spark, how it works, the benefits it offers, and how the right partner can streamline and simplify Spark deployments in almost any organization.
From Hadoop to SQL: The Apache Spark Ecosystem
Like all distributed computing frameworks, Apache Spark works by distributing massive computing tasks to multiple nodes, where they are broken down into smaller tasks that can be processed simultaneously.
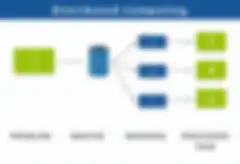
But Spark’s groundbreaking, in-memory data engine gives it the ability to perform most compute jobs on the fly, rather than requiring multi-stage processing and multiple read-and-write operations back and forth between memory and disk.
This important distinction enables Spark to power through multi-stage processing cycles like those used in Apache Hadoop up to 100 times faster. Its speed, plus an easy-to-master API, has made Spark a default tool for major corporations and developers.
Apache Spark vs Hadoop and MapReduce
That’s not to say Hadoop is obsolete. It does things that Spark does not, and often provides the framework upon which Spark works. The Hadoop Distributed File System enables the service to store and index files, serving as a virtual data infrastructure.
Spark, on the other hand, performs distributed, high-speed compute functions on that architecture. If Hadoop is the professional kitchen with the tools and equipment to build and cook meals of data, then Spark is the expediter that rapidly assembles and distributes those meals for consumption.
It’s important to recognize that not every organization needs Spark’s advanced speed. Hadoop already uses a system called MapReduce to accelerate distributed processing, and can crunch data sets up to a terabyte incredibly fast. It does this by simultaneously mapping parallel jobs to specific locations for processing and retrieval, and reducing returned data by comparing sets for duplicates and errors, and delivering “clean” information.
MapReduce performs these jobs so quickly that only the most data-intensive operations are likely to require the speed Spark enables. Some of these include:
- Social media services
- Telecom
- Multimedia streaming service providers
- Large-scale data analysis
Because Spark was built to work with and run on the Hadoop infrastructure, the two systems work well together. Fast-growing organizations built in Hadoop can easily add Spark’s speed and functionality as needed.
Check out this short video for more on getting more out of Hadoop with Apache Spark:
Spark SQL
Spark SQL is Apache’s module for working with structured data. Included as a module in the Spark download, Spark SQL provides integrated access to the most popular data sources, including Avro, Hive, JSON, JDBC, and others.
Spark SQL sorts data into named columns and rows ideal for returning high-speed queries. Best of all, it integrates seamlessly with new and existing Spark applications for optimum performance and minimal compute costs.
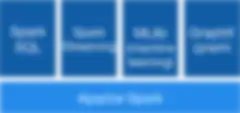
Image courtesy of Apache Spark
Spark SQL is one tool in an Apache Spark ecosystem that also includes Spark Batch, Spark Streaming, MLlib (the machine learning component), and GraphX. Below is a look at the role the other modules play in powering the Spark world.
- Spark Streaming — Spark may be the perfect tool for extremely fast analysis of batch data, but what happens when a repository is affected by real-time data changes? Enter Spark Streaming, which runs on top of a Spark install and adds interactive analytics capabilities for real-time data ingested from almost any popular repository source. Spark Streaming powers robust applications that require real-time data and comes with Spark’s reliable fault tolerance, making the tool a powerful weapon in development arsenals.
- MLlib — MLlib (Machine Learning Library) also runs natively atop Apache Spark, providing fast, scalable machine learning. MLlib utilizes Spark’s APIs and works seamlessly with any Hadoop data source. MLib provides reliable algorithms and incredible speed to construct and maintain machine learning libraries that power business intelligence.
- GraphX — Build and manipulate graph data to perform comparative analytics on your Spark platform with GraphX. Transform and merge structured data at speeds among the fastest in the industry. Use the friendly GUI to choose from a growing collection of algorithms, or build custom ones to track ETL insights.
All of these components of the Spark ecosystem interact seamlessly and operate with minimal overhead, making Spark a powerful, scalable platform.
The Benefits of Apache Spark
For companies that rely on big data to excel, Spark comes with a handful of distinct advantages over competitors:
- Speed — As mentioned, Spark’s speed is its most popular asset. Spark’s in-memory processing engine is up to 100 times faster than Hadoop and similar products, which require read, write, and network transfer time to process batches..
- Fault tolerance — The Spark ecosystem operates on fault tolerant data sources, so batches work with data that is known to be ‘clean.’ But when streaming data interacts with sources an additional layer of tolerance is needed. Spark replicates streaming data to diverse nodes in real-time, and achieves fault tolerance by comparing remote streams to the original stream. In this way, Spark incorporates high reliability for even live-streamed data.
- Minimized hand coding — Spark adds a GUI interface that Hadoop lacks, making it easier to deploy without extensive hand coding. Though sometimes manual customization best suits application challenges, the GUI offers quick and easy options for achieving common tasks.
- Usability — Spark’s core APIs are compatible with Java, Scala, Python, and R, making it easy to build rand scale robust applications.
- Active developer community — Industry giants like Hitachi Solutions, TripAdvisor, and Yahoo have successfully deployed the Spark ecosystem at massive scale. A global support and development community backs Spark and routinely improves builds.
If an organization identifies needs in these areas, Apache Spark brings proven solutions and unmatched processing speed to big data operations.
How It Works
Built to operate almost seamlessly in existing architectures, Apache Spark supports four types of installs:
- Local
- Stand alone
- YARN Client
- YARN Cluster
Each type of install uses a slightly different approach to tasks, but all big data operations in Spark are divided into either Spark Batch or Spark Streaming jobs.
Spark Batch — Batch jobs analyze data that has been collected (historic) into one or more data stores. Batch jobs deliver information from repositories for analysis.
Spark Streaming — The Spark analytics tool ingests streaming data in real-time, with analytics tools that provide insights across both streaming and historical data so experts can manage data as it changes.
For a more detailed look at working with Spark Batch and Streaming and their associated components, reference this Spark technical primer.
Talend and Apache Spark
Talend Big Data provides the platform organizations need to unleash the power of Spark quickly and with immediate impact. Here are five ways Talend simplifies and improves the Spark experience:
- Unified Operations — Talend provides a single solution source for all on-premises, cloud, or hybrid environments, bringing big data under complete control from intuitive interfaces that non-developers can interpret and manipulate.
- Visual Design Tools — Talend enables non-coders to build and edit jobs in Spark, Spark Streaming, and Spark MLlib. Reducing the technical complexity of big data tasks makes deep business intelligence more accessible to organizational decision makers.
- Simplified Compliance — An increasingly regulated online business world comes with regulatory minefields that can prove expensive and time-consuming for almost any business. Talend provides the tools and insights to master compliance challenges like HIPPA, PCI DSS, Sarbanes-Oxley, the European General Data Protection Regulation (GDPR), and more by providing fraud protection, data governance solutions, risk mitigation, and more, so organizations can focus on business, not compliance.
- Leveraged Machine Learning — Prebuilt, drag and drop developer components and a wide variety of prebuilt and customizable algorithms let developers and data scientists leverage machine learning through Spark’s friendly, GUI tools.
- Lowered Total Cost of Ownership — Through the Talend management interface, Apache Spark includes data preparation as a service, bringing Spark online in any environment in just minutes. Simplified maintenance and light-weight graphic design tools leverage the full power of the Spark ecosystem while lowering investments in time and compute overhead expenses.
Learn more about how Talend can harness data agility with Hadoop and Spark.
Getting Started with Apache Spark
Apache Spark is a leading distributed framework featuring ultra-fast operations and advanced analytics. Exponentially improving upon the speed of the Hadoop framework, Spark adds complex streaming analysis, a fast and seamless install, and a low learning curve so professionals can improve business intelligence today.
Talend’s single-point management solution adds to Spark’s friendly, GUI deployment tools, improved machine learning, and powerful analytics tools to make it easy to achieve increased data agility.
Get started today by downloading the latest release of Apache Spark, with pre-configured options for unique environment builds. Then download the Talend Big Data Sandbox to start experimenting with unified management in Spark, Spark Streaming, and other cutting edge big data technologies.

More related articles
- Big Data and Agriculture: A Complete Guide
- Big Data and Privacy: What Companies Need to Know
- 5 Ways to Optimize Your Big Data
- Big Data for Supply Chain Management
- Big Data in Government
- Defining Big Data Analytics for the Cloud
- Big Data in Media and Telco: 6 Applications and Use Cases
- 7 Ways Big Data is Changing E-commerce
- How Big Data is Changing Healthcare
- 2 Key Challenges of Streaming Data and How to Solve Them
- Big Data for Small Business: A Complete Guide
- How Does Big Data Work for HR Analytics?
- What is Hadoop?
- What is MapReduce?
- What is Big Data? Free Guide and Definition
- Beginner’s Guide to Batch Processing
- An Intro to Apache Spark Partitioning
- Big Data in Finance - Your Guide to Financial Data Analysis
- Talend Performance Tuning Strategy
- Stream Processing Defined
- Big Data in Marketing 101
- Big Data in Retail: Common Benefits and 7 Real-Life Examples